Можно поймать панику во всём тесте с помощью ключа #[should_panic]:
#[test]#[should_panic(expected = "assertion failed")]fntest_example(){letroom_nums=[1,2,3,4];letmax_length=room_nums.len();letindex_out_of_bounds=room_nums.get(max_length+1);assert!(index_out_of_bounds.is_some());// паника будет тут
}
❗Если паники по факту не будет, тест провалится.
Можно перехватить панику в конкретной команде с помощью std::panic::catch_unwind():
В библиотеках требуется получать на выходе конкретный тип ошибки, поэтому там применяется thiserror.
Установка
cargo add anyhow
Использование
Anyhow создаёт алиас наподобие Result<T> = Result<T, Box<dyn Error>>, чтобы скрыть тип ошибок и сделать его универсальным.
// ---- Без Anyhow
fnstring_error()-> Result<(),String>{Ok(())}fnio_error()-> Result<(),std::io::Error>{Ok(())}fnany_error()-> Result<(),Box<dynError>>{string_error()?;io_error()?;Ok(())}// ---- С Anyhow:
useanyhow::Result;fnstring_error()-> Result<()>{Ok(())}fnio_error()-> Result<()>{Ok(())}fnany_error()-> Result<()>{string_error()?;io_error()?;Ok(())}
Пример неудачного чтения файла:
useanyhow::{Context,Result};fnread_config_file(path: &str)-> Result<String>{std::fs::read_to_string(path).with_context(||format!("Failed to read file {}",path))}fnmain()-> Result<()>{letconfig_content=read_config_file("conf.txt")?;println!("Config content:\n{:?}",config_content);Ok(())}
Result<T> становится алиасом к Result<T, anyhow::Error>;
Context, with_context() позволяет добавить подробности к ошибке, в случае неуспеха функции чтения read_to_string();
Оператор ? выносит ошибку вверх, при этом авто-конвертирует её тип в anyhow::Error.
Замена Box<dyn> с контекстом
Возьмём пример, в котором чтение файла std::fs::read_to_string() (может быть неудачным), далее дешифровка его контента с помощью base64 decode() (может не получиться) в цепочку байт, из которой формируется строка String::from_utf8() (может не получиться). Все эти три потенциальных ошибки имеют разный тип.
Один способ все три их принять на одну функцию, это с помощью Box<dyn std::error::Error>>, потому что все 3 ошибки применяют std::error::Error.
Подход рабочий, но при срабатывании одной из трёх ошибок, судить о происхождении проблемы можно будет лишь по сообщению внутри ошибки.
В случае применения Anyhow, можно заменить им Box<dyn>, при этом сразу добавить контекстные сообщения, которое поможет понять место:
useanyhow::Context;usebase64::{self,engine,Engine};fndecode()-> Result<(),anyhow::Error>{letinput=std::fs::read_to_string("input").context("Failed to read file")?;// контекст 1
forlineininput.lines(){letbytes=engine::general_purpose::STANDARD.decode(line).context("Failed to decode the input")?;// контекст 2
println!("{}",String::from_utf8(bytes).context("Failed to cenvert bytes")?// контекст 3
);}Ok(())
Замена map_err()
map_err() - это универсальный метод из стандартной библиотеки, который работает с любым Result. context() - это метод из anyhow, специально созданный для удобного добавления контекста к ошибкам.
// map_err — нужно явно создавать anyhow::Error
.map_err(|e|anyhow::anyhow!("ошибка: {}",e))// context — просто добавляет пояснение
.context("ошибка")?
context() принимает замыкание (closure), которое выполняется только при ошибке. Это важно для ресурсоемких операций:
// context с замыканием — форматирование только при ошибке
letcontent=std::fs::read_to_string(path).with_context(||format!("не удалось прочитать файл {}",path))?;// map_err — форматирование всегда, даже при успехе
letcontent=std::fs::read_to_string(path).map_err(|e|anyhow::anyhow!("не удалось прочитать файл {}",path))?;
with_context() - вариант context() с ленивым вычислением, идеален для дорогих операций вроде форматирования строк.
При запуске данная программа требует 2 аргумента, притом второй обязательно числом.
Добавление описаний
Имя программы и версия вносятся отдельным признаком. Доп. поля описания вносятся с помощью спец. комментариев ///:
useclap::Parser;#[derive(Parser, Debug)]#[command(author = "Author Name", version, about)]/// A very simple CLI parser
structArgs{/// Text argument option
arg1: String,/// Number argument option
arg2: usize,}fnmain(){letargs=Args::parse();println!("{:?}",args)}
Добавка флагов
Флаги добавляем с помощью аннотации #[arg(short, long)] для короткого и длинного именования флага. Если у 2-х флагов одинаковая первая буква, можно указать вручную их короткую версию. Короткая версия не может быть String, можно только 1 char.
<..>structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(short = 'A', long)]/// Number argument option
arg2: usize,}<..>
Необязательные флаги
Для отметки аргумента как необязательного достаточно указать его тип как Option<тип> и в скобках исходный тип данных:
structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(short = 'A', long)]/// Number argument option
arg2: Option<usize>,}
Такой подход потребует обработать ситуацию, когда в arg2 ничего нет. Вместо так делать, можно указать значение по умолчанию:
structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(default_value_t=usize::MAX, short = 'A', long)]/// Number argument option
arg2: usize,}
Теперь arg2 по умолчанию будет равен максимальному числу usize, если не указано иное.
Валидация введённых значений
В случае аргумента-строки есть возможность ввести пустую строку из пробелов " ". Для исключения таких вариантов, вводится функция валидации и её вызов:
useclap::Parser;#[derive(Parser, Debug)]#[command(author = "Author Name", version, about)]/// A very simple CLI parser
structArgs{#[arg(value_parser = validate_argument_name, short = 'a', long)]/// Text argument option
arg1: String,#[arg(default_value_t=usize::MAX, short = 'A', long)]/// Number argument option
arg2: usize,}fnvalidate_argument_name(name: &str)-> Result<String,String>{ifname.trim().len()!=name.len(){Err(String::from("строка не должна начинаться или заканчиваться пробелами",))}else{Ok(name.to_string())}}fnmain(){letargs=Args::parse();println!("{:?}",args)}
Теперь при попытке вызвать программу tiny-clapper -- -a " " будет показана ошибка валидации.
❗Ограничение - можно вызывать только существующие объекты, нельзя добавлять свой текст.
spawn - гибкий ввод
Самый гибкий вариант, позволяющий делать свой ввод, а не только существующие команды и файлы-папки, это через spawn:
letmutchild=Command::new("cat")// команда
.stdin(Stdio::piped()).stdout(Stdio::piped()).spawn()?;letstdin=child.stdin.as_mut()?;stdin.write_all(b"Hello Rust!\n")?;// текст к команде, /n обязателен
letoutput=child.wait_with_output()?;foriinoutput.stdout.iter(){// цикл на случай многострочного вывода
print!("{}",*iaschar);}Ok(())
❗Ограничение - можно подавать на вход текст лишь тем командам, которые требуют сразу указать вводный текст. При этом ряд команд делают паузу перед потреблением текста на вход, с такими свой ввод работать не будет это относится и к фильтрации через pipe = | grep <...> и аналоги.
Pipe (nightly) - полный ввод (не проверенный способ)
#![feature(anonymous_pipe)]// только в Rust Nightly
usestd::pipelettext="| grep file".as_bytes();// Запускаем саму команду
letchild=Command::new("ls").arg("/Users/test").stdin({// Нельзя отправить просто строку в команду
// Нужно создать файловый дескриптор (как в обычном stdin "pipe")
// Поэтому создаём пару pipes тут
let(reader,mutwriter)=std::pipe::pipe().unwrap();// Пишем строку в одну pipe
writer.write_all(text).unwrap();// далее превращаем вторую для передачи в команду сразу при spawn.
Stdio::from(reader)}).spawn()?;
Sorting() a string of letters (with rev() - reverse order)
useitertools::Itertools;lettext="Hello world";lettext_sorted=text.chars().sorted().rev().collect::<String>();// rev() - Iterate the iterable in reverse
println!("Text: {}, Sorted Text: {}",text,text_sorted);// Text: Hello world, Sorted Text: wroollledH
Counts() подсчёт количества одинаковых элементов в Array
useitertools::Itertools;letnumber_list=[1,12,3,1,5,2,7,8,7,8,2,3,12,7,7];letmode=number_list.iter().counts();// Itertools::counts()
// возвращает HashmapHashMap<char, usize>,
// где ключи взяты из массива, значения - частота
for(key,value)in&mode{println!("Число {key} встречается {value} раз");}
По сути counts() создаёт HashMap, заменяя собой конструкцию или конструкцию на базе fold():
userand::Rng;fnmain(){letsecret_of_type=rand::rng().random::<u32>();letsecret=rand::rng().random_range(1..=100);println!("Random nuber of type u32: {secret_of_type}");println!("Random nuber from 1 to 100: {}",secret);}
В старой версии библиотеки применялся признак gen(), который переименовали в связи с добавлением gen() в Rust 2024.
. any character except new line (includes new line with s flag)
\d digit (\p{Nd})
\D not digit
\pX Unicode character class identified by a one-letter name
\p{Greek} Unicode character class (general category or script)
\PX Negated Unicode character class identified by a one-letter name
\P{Greek} negated Unicode character class (general category or script)
Классы символов
[xyz] A character class matching either x, y or z (union).
[^xyz] A character class matching any character except x, y and z.
[a-z] A character class matching any character in range a-z.
[[:alpha:]] ASCII character class ([A-Za-z])
[[:^alpha:]] Negated ASCII character class ([^A-Za-z])
[x[^xyz]] Nested/grouping character class (matching any character except y and z)
[a-y&&xyz] Intersection (matching x or y)
[0-9&&[^4]] Subtraction using intersection and negation (matching 0-9 except 4)
[0-9--4] Direct subtraction (matching 0-9 except 4)
[a-g~~b-h] Symmetric difference (matching `a` and `h` only)
[\[\]] Escaping in character classes (matching [ or ])
Совмещения символов
xy concatenation (x followed by y)
x|y alternation (x or y, prefer x)
Повторы символов
x* zero or more of x (greedy)
x+ one or more of x (greedy)
x? zero or one of x (greedy)
x*? zero or more of x (ungreedy/lazy)
x+? one or more of x (ungreedy/lazy)
x?? zero or one of x (ungreedy/lazy)
x{n,m} at least n x and at most m x (greedy)
x{n,} at least n x (greedy)
x{n} exactly n x
x{n,m}? at least n x and at most m x (ungreedy/lazy)
x{n,}? at least n x (ungreedy/lazy)
x{n}? exactly n x
Пустые символы
^ the beginning of text (or start-of-line with multi-line mode)
$ the end of text (or end-of-line with multi-line mode)
\A only the beginning of text (even with multi-line mode enabled)
\z only the end of text (even with multi-line mode enabled)
\b a Unicode word boundary (\w on one side and \W, \A, or \z on other)
\B not a Unicode word boundary
Группировка и флаги
(exp) numbered capture group (indexed by opening parenthesis)
(?P<name>exp) named (also numbered) capture group (names must be alpha-numeric)
(?<name>exp) named (also numbered) capture group (names must be alpha-numeric)
(?:exp) non-capturing group
(?flags) set flags within current group
(?flags:exp) set flags for exp (non-capturing)
Спец-символы
\* literal *, works for any punctuation character: \.+*?()|[]{}^$
\a bell (\x07)
\f form feed (\x0C)
\t horizontal tab
\n new line
\r carriage return
\v vertical tab (\x0B)
\123 octal character code (up to three digits) (when enabled)
\x7F hex character code (exactly two digits)
\x{10FFFF} any hex character code corresponding to a Unicode code point
\u007F hex character code (exactly four digits)
\u{7F} any hex character code corresponding to a Unicode code point
\U0000007F hex character code (exactly eight digits)
\U{7F} any hex character code corresponding to a Unicode code point
Первое совпадение будет иметь тип Option<match>, а в случае отсутствия совпадений = None.
Поиск всех совпадений
letpattern=regex::Regex::new(r"hello, (world|universe)!")?;letinput="hello, world! hello, universe!";letmatches: Vec<_>=pattern.find_iter(input).collect();// find_iter()
matches.iter().for_each(|i|println!("{}",i.as_str()));// matches = Vec<match> и содержит все совпадения
Add serde framework with Derive feature to use it in structures and functions. Also add a separate serde_json lib for converting into specifically JSON:
cargo add serde -F derive
cargo add serde_json
Usage
Add serde, then mark the structures with Serialise, Deserialise traits and use serde_json for serialising:
useserde::{Deserialize,Serialize};#[derive(PartialEq, Debug, Clone, Serialize, Deserialize)]pubenumLoginRole{Admin,User,}#[derive(Debug, Clone, Serialize, Deserialize)]pubstructUser{pubusername: String,pubpassword: String,pubrole: LoginRole,}pubfnget_default_users()-> HashMap<String,User>{letmutusers=HashMap::new();users.insert("admin".to_string(),User::new("admin","password",LoginRole::Admin),);users.insert("bob".to_string(),User::new("bob","password",LoginRole::User),);users}pubfnget_users()-> HashMap<String,User>{letusers_path=Path::new("users.json");ifusers_path.exists(){// Load the file!
letusers_json=std::fs::read_to_string(users_path).unwrap();letusers: HashMap<String,User>=serde_json::from_str(&users_json).unwrap();users}else{// Create a file and return it
letusers=get_default_users();letusers_json=serde_json::to_string(&users).unwrap();std::fs::write(users_path,users_json).unwrap();users}
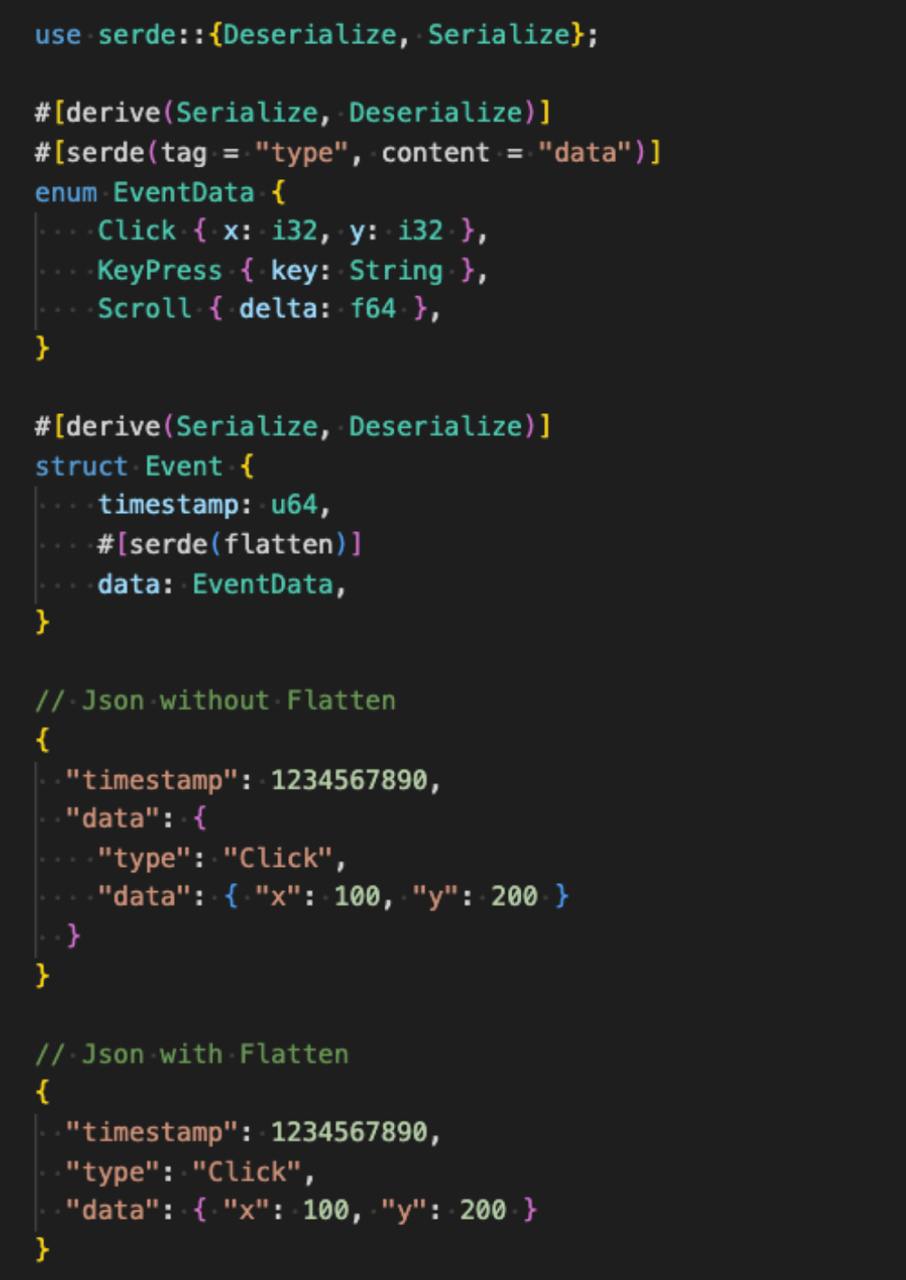
Flatten
Если при сериализации в JSON вы хотите, чтобы вложенные структуры или enum выглядели как часть общего объекта, используйте атрибут #[serde(flatten)]
Он убирает лишние уровни вложенности и делает JSON более читаемым и удобным:
usestd::process;// номер процесса PID вывести
usesysinfo::{RefreshKind,System};fnmain(){let_sys=System::new_with_specifics(RefreshKind::nothing());letpid=process::id();println!("System name: {:?}",System::name());println!("System kernel version: {:?}",System::kernel_version());println!("System OS version: {:?}",System::os_version());println!("System host name: {:?}",System::host_name());println!("Process ID: {}",pid);}
С помощью RefreshKind::nothing() отключаются все динамические вещи, такие как остаток свободной памяти, загрузка ЦПУ, сеть и так далее, что драматически ускоряет опрос системы.
Можно частично опрашивать разные системные ресурсы, по заданным интервалам.
usethiserror::Error;#[derive(Error, Debug)]pubenumMyLibError{#[error("Network failed: {0}")]Network(String),#[error("Invalid user ID: {id}")]InvalidUserId{id: u32},#[error("File not found")]NotFound,#[error("IO error: {0}")]Io(#[from]std::io::Error),}
#[from] в Io означает ? превращает std::io::Error в MyLibError::Io(...).
Все функции библиотеки возвращают Result с ошибкой в MyLibError:
pubfnget_user(id: u32)-> Result<String,MyLibError>{ifid==0{returnErr(MyLibError::InvalidUserId{id});}std::fs::read_to_string("config.txt")?;// автоконвертирует тип ошибки
Ok(format!("User {}",id))}
Особенность применения:
Для работы с ошибками в БИБЛИОТЕКАХ (libs)!
В приложениях проще унифицировать тип ошибки, поэтому там применяется anyhow.
Пользователи библиотеки могут проверять по конкретным ошибкам:
useyour_lib::{get_user,MyLibError};matchget_user(0){Ok(name)=>println!("Got {name}"),Err(MyLibError::InvalidUserId{id})=>{println!("You gave ID {id}, but that's invalid!");// обработать конкретно
}Err(MyLibError::NotFound)=>{println!("File missing, creating new one...");// создать файл
}Err(e)=>{println!("Other error: {e}");}}
В случае с anyhow, пользователи получили бы единый тип anyhow::Error и вынуждены были бы парсить строки (плохой код).
Пример применения:
// Библиотека (image_loader.rs)
#[derive(thiserror::Error, Debug)]pubenumImageError{#[error("File too large: {size} bytes")]TooLarge{size: u64},#[error("Unsupported format: {format}")]BadFormat{format: String},#[error("Corrupted data")]Corrupted,}pubfnload_image(path: &str)-> Result<Vec<u8>,ImageError>{// ...
}// Кто-то используем библиотеку:
matchimage_loader::load_image("photo.png"){Ok(data)=>render(data),Err(ImageError::TooLarge{size})=>println!("Your image is {size} bytes, max is 10MB"),Err(ImageError::BadFormat{format})=>println!("Sorry, we don't support {format} files"),Err(ImageError::Corrupted)=>println!("The image is broken"),}
Наблюдаемость позволяет понять систему извне, задавая вопросы о ней, при этом не зная ее внутреннего устройства. Кроме того, она позволяет легко устранять неполадки и решать новые проблемы, то есть «неизвестные неизвестные». Она также поможет вам ответить на вопрос «почему что-то происходит?».
Чтобы задать эти вопросы о вашей системе, приложение должно содержать полный набор инструментов. То есть код приложения должен отправлять сигналы, такие как трассировки, метрики и журналы. Приложение правильно инструментировано, когда разработчикам не нужно добавлять дополнительные инструменты для устранения неполадок, потому что у них есть вся необходимая информация.
Терминология
Событие журнала (Log event/message) - событие, произошедшее в конкретный момент времени;
Промежуток (Span record) - запись потока исполнения в системе за период времени. Он также выполняет функции контекста для событий журнала и родителя для под-промежутков;
Трасса (trace) - полная запись потока исполнения в системе от получения запроса до отправки ответа. Это по сути промежуток-родитель, или корневой промежуток;
Подписчик (subscriber) - реализует способ сбора данных трассы, например, запись их в стандартный вывод;
Контекст трассировки (Tracing Context): набор значений, которые будут передаваться между службами
usetracing::info;fnmain(){// Установка глобального сборщика по конфигурации
tracing_subscriber::fmt::init();letnumber_of_yaks=3;// новое событие, вне промежутков
info!(number_of_yaks,"preparing to shave yaks");}
Ручная инициализация свойств подписчика для форматирования лога:
fnsetup_tracing(){letsubscriber=tracing_subscriber::fmt().json()// нужно cargo add tracing-subscriber -F json
.with_max_level(tracing::Level::TRACE)// МАХ уровень логирования
.compact()// компактный лог
.with_file(true)// показывать файл-исходник
.with_line_number(true)// показать номера строк кода
.with_thread_ids(true)// показать ID потока с событием
.with_target(false)// не показывать цель (модуль) события
.finish();tracing::subscriber::set_global_default(subscriber).unwrap();tracing::info!("Starting up");tracing::warn!("Are you sure this is a good idea?");tracing::error!("This is an error!");}
Макрос #[instrument] автоматически создаёт промежутки (spans) для функций, а подписчик (subscriber) настроен выводить промежутки в stdout.
Трассировка потоков в асинхронном режиме
usetracing_subscriber::fmt::format::FmtSpan;#[tracing::instrument]// инструмент следит за временем работы
asyncfnhello(){tokio::time::sleep(tokio::time::Duration::from_secs(1)).await;}#[tokio::main]// cargo add tokio -F time,macros,rt-multi-thread
asyncfnmain()-> anyhow::Result<()>{letsubscriber=tracing_subscriber::fmt().json().compact().with_file(true).with_line_number(true).with_thread_ids(true).with_target(false).with_span_events(FmtSpan::ENTER|FmtSpan::CLOSE)// вход и выход
.finish();// потока отслеживать
tracing::subscriber::set_global_default(subscriber).unwrap();hello().await;Ok(())}
В итоге получаем лог работы потока с временем задержки:
2024-12-24T14:30:17.378906Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383596Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383653Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383675Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"close","time.busy":"179µs","time.idle":"1.00s"}{}
Для записи журнала применяется отдельный модуль tracing-appender:
cargo add tracing-appender
У него много функций не только записи в облачные службы типа Datadog, но и создание журнала с дозаписью (минутной, часовой, дневной), а также запись как неблокирующее действие во время многопоточного исполнения.
Пример инициализации неблокирующей записи журнала в файл (лучше всего как JSON), одновременно вывод на экран и организация часового журнала с дозаписью (rolling):
usetracing::{instrument,warn};// тянем std::io::Write признак в режиме неблокирования
usetracing_subscriber::fmt::writer::MakeWriterExt;fnsetup_tracing(){// инициализация файла с дозаписью
letlogfile=tracing_appender::rolling::hourly("/some/directory","app-log");// уровень записи при логировании = INFO
letstdout=std::io::stdout.with_max_level(tracing::Level::INFO);letsubscriber=tracing_subscriber::fmt().with_max_level(tracing::Level::TRACE).json().compact().with_file(true).with_line_number(true).with_thread_ids(true).with_target(false).with_writer(stdout.and(logfile))// обязательно указать запись тут
.finish();// в файл и в stdout консоль
tracing::subscriber::set_global_default(subscriber).unwrap();}#[instrument]fnsync_tracing(){warn!("event 1");sync_tracing_sub();}#[instrument]fnsync_tracing_sub(){warn!("event 2");}fnmain(){setup_tracing();sync_tracing();}
Инициализация единого трассировщика на проекте
В составе Workspace трассировщик следует инициализировать единожды и далее использовать во всём проекте.
Для этого на верхнем уровне Workspace в Cargo.toml вписываем зависимость с применением по всему Workspace:
usecommon_log::setup_tracing;usetracing::{debug,error,info,warn};fnmain(){setup_tracing();// инициализация логгера из библиотеки common-log
info!("Logger initialized. App started.");// вызов логгера
}
Лог будет сохранён в папке /log/ в бинарном крейте, так как из него делается вызов инициализации.
Использование в тестах
#[cfg(test)]modtests{usesuper::*;usecommon_logging::setup_tracking;#[test]fntest_something(){init_test_logger();// ваш тест
}}
Настройка через переменные окружения
# Установка уровня логированияRUST_LOG=debug cargo run
RUST_LOG=my_library=debug,info cargo run
# Для конкретного крейтаRUST_LOG=my_library=debug cargo run