Image manifest указывает на расположение конфига и набора слоёв для образа контейнера на конкретной ОС и архитектуре. Поле size указывает общий размер объекта. Теперь можно исследовать далее:
Распакуем базовый первый слой из архива и изучим его:
$ mkdir rootfs
$ tar -C rootfs -xf mysterious-image/blobs/sha256/0503825856099e6adb39c8297af09547f69684b7016b7f3680ed801aa310baaa
$ tree -L 1 rootfs/
rootfs/
├── bin
├── dev
├── etc
├── home
├── lib
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
Это файловая система ОС! Можно изучить версию дистрибутива
$ cat rootfs/etc/issue
Welcome to Alpine Linux 3.10
Kernel \r on an \m(\l)$ cat rootfs/etc/os-release
NAME="Alpine Linux"ID=alpine
VERSION_ID=3.10.1
PRETTY_NAME="Alpine Linux v3.10"HOME_URL="https://alpinelinux.org/"BUG_REPORT_URL="https://bugs.alpinelinux.org/"
Распакуем следующий слой и изучим его:
$ tar -C layer -xf mysterious-image/blobs/sha256/6d8c9f2df98ba6c290b652ac57151eab8bcd6fb7574902fbd16ad9e2912a6753
$ tree -L 1 layer/
layer/
└── my-file
1 directory, 1 file
Тут лежим доп файл, созданный командой "/bin/sh -c touch my-file" - это можно увидеть в секции history. По сути исходный Dockerfile выглядел так:
FROMalpine:latestRUNecho HelloRUN touch my-file
Buildah
В 2017 году Red Hat разработали инструмент для создания образов контейнеров по стандарту OCI - как аналог docker build.
Создадим Dockerfile vim Dockerfile и впишем в него:
FROMalpine:latestRUNecho HelloRUN touch my-file
Запустим сборку контейнера на базе этого файла - buildah bud
Buildah поддерживает много команд:
buildah images # список образовbuildah rmi # удалить все образыbuildah ps # показать запущенные контейнеры
Почему вдруг buildah ps показ запущенных контейнеров, когда это инструмент для их СОЗДАНИЯ? А потому что в процессе создания как в buildah, так и в docker идёт запуск промежуточных контейнеров, их модификация в runtime. Каждый шаг модификации создаёт записи в history. Это потенциальная проблема ИБ: можно влезть в контейнер, пока он собирается (и запущен), если там что-то большое, и модифицировать его.
> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
05f4aa4aa95c 54da47293a0b "/bin/sh -c 'apt-get…"11 seconds ago Up 11 seconds interesting_heyrovsky
> docker exec -it 05f4aa4aa95c sh
# echo "Hello world" >> my-file
После сборки можно удостовериться, что созданный файл на месте:
> docker run clang cat my-file
Hello world
Создание контейнеров без Dockerfile
У buildah есть императивные команды к любой команде из Dockerfile, типа RUN или COPY. Это даёт огромную гибкость, т.к вместо огромных Dockerfile можно делить процесс создания контейнеров на части, между ними запускать любые вспомогательные инструменты UNIX.
Создадим базовый контейнер с Alpine Linux и посмотрим как он работает:
buildah from alpine:latest
buildah ps
Можно запускать команды в контейнере, а также создать в нёс файл:
По-умолчанию, buildah не делает записи history в контейнер, это значит порядок команд и частота их вызова не влияют на итоговые слои. Можно поменять это поведение ключом --add-history или переменной ENV BUILDAH_HISTORY=true.
Сделаем коммит нового контейнера в образ для финализации процесса:
buildah commit alpine-working-container my-image
buildah images # новый образ теперь в локальном реестре
Можно выпустить образ в реестр Docker, либо на локальный диск в формате OCI:
buildah unshare создаёт новое пространство имён, что позволяет подключить файловую систему как текущий не-root пользователь;
--mount автоматически подключает, путь кладём в переменную среды MOUNT;
Далее мы делаем commit на изменения, и mount на автомате убирается при покидании buildah unshare сессии.
Мы успешно модифицировали файловую систему контейнера через локальный mount. Проверим наличие файла:
> buildah run -t alpine-working-container cat test-from-mount
it-works
Вложенные контейнеры
У buildah нет даемона, значит, не нужно подключать docker.sock в контейнер для работы с Docker CLI. Это даёт гибкость и возможность делать вложенные схемы: установим buildah в контейнер, созданный buildah:
> buildah from opensuse/tumbleweed
tumbleweed-working-container
> buildah run -t tumbleweed-working-container bash
# zypper in -y buildah
Теперь вложенный buildah готов к использованию. Нужно указать драйвер хранения VFS в контейнере, чтобы получить рабочий стек файловой системы:
# buildah --storage-driver=vfs from alpine:latest# buildah --storage-driver=vfs commit alpine-working-container my-image
Получили вложенный контейнер. Заложим его в хранилище на локальной машине -> для начала заложим образ в /my-image:
ВАЖНОЕ ЗАМЕЧАНИЕ: все действия с buildah не потребовали sudo. Buildah создаёт всё необходимое для каждого пользователя в папках:
~/.config/containers, конфигурация
~/.local/share/containers, хранилища контейнеров
Декомпозиция Dockerfile в несколько разных с помощью CPP макросов.
podman
Инструмент для замены Docker. podman использует buildah как API для создания Dockerfile с помощью podman build. Это значит, что они разделяют одно хранилище под капотом. А это значит, что podman может запускать созданные buildah контейнеры:
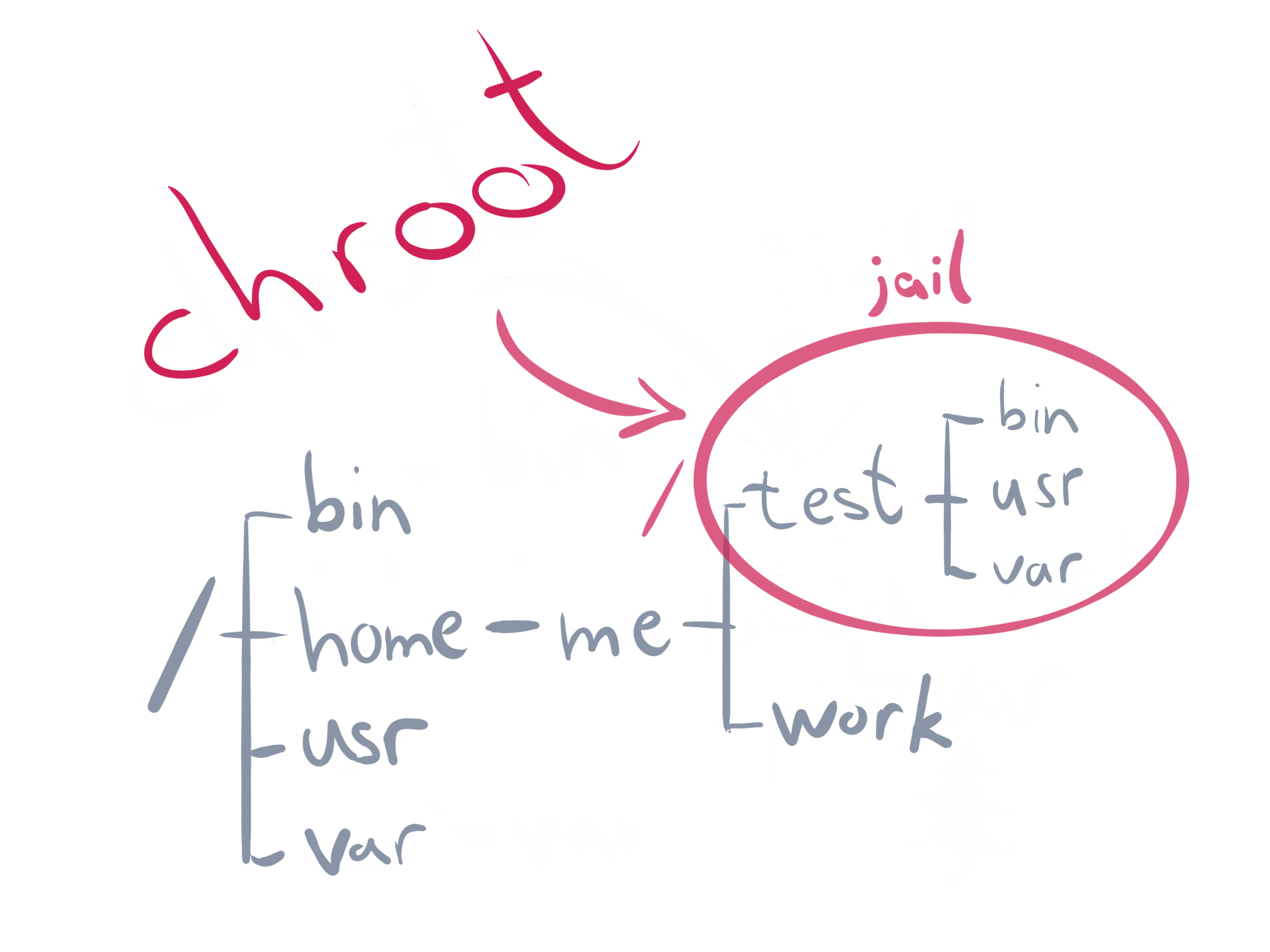
chroot - утилита, которая предназначена для изоляции файловой среды приложения. Создана в Minix 1.7. Для процессов и ОЗУ не подходит, но вдохновила создание Namespaces в Linux позднее.
Пример работы
Для работы bash в новой среде chroot необходимо внести его копию в папку jail:
Либо, гораздо проще перенести разом все библиотеки:
cp -a /usr jail/
cp -a /lib jail/
cp -a /lib64 jail/
Далее, заход в окружение:
sudo chroot $HOME/jail /bin/bash
bash-5.0# ls
bin lib lib64 usr
#### Побег из chroot```c
#include <sys/stat.h>#include <unistd.h>int main(void){ mkdir(".out", 0755); // нужны права root в контейнере
chroot(".out"); chdir("../../../../../"); // относительный путь за пределы корня
chroot(".");return execl("/bin/bash", "-i", NULL);}
Only privileged processes with the capability CAP_SYS_CHROOT are able to call chroot.
Modern systems use pivot_mount (calling process must have the CAP_SYS_ADMIN capability). - has the benefit of putting the old mounts into a separate directory on calling.
Linux Namespaces
Задача: обернуть системные ресурсы в уровень абстракции;
Introduced in Linux 2.4.19 (2002), became “container ready” in 3.8 in 2013 with the introduction of the user namespace;
Seven distinct namespaces implemented: mnt, pid, net, ipc, uts, user, cgroup; time and syslog introduced in 2016;
функция clone . Создаёт дочерние процессы. Unlike fork(2), the clone(2) API allows the child process to share parts of its execution context with the calling process, such as the memory space, the table of file descriptors, and the table of signal handlers. You can pass different namespace flags to clone(2)to create new namespaces for the child process.
unshare(2) - отсоединение частей контекста выполнения процесса.
setns(2) позволяет запрашивающему процессу присоединяться в разные namespaces.
proc - Besides the available syscalls, the proc filesystem populates additional namespace related files. Since Linux 3.8, each file in /proc/$PID/ns is a “magic“ link which can be used as a handle for performing operations (like setns(2)) to the referenced namespace.
> ls -Gg /proc/self/ns/
total 0lrwxrwxrwx 10 Feb 6 18:32 cgroup -> 'cgroup:[4026531835]'lrwxrwxrwx 10 Feb 6 18:32 ipc -> 'ipc:[4026531839]'lrwxrwxrwx 10 Feb 6 18:32 mnt -> 'mnt:[4026531840]'lrwxrwxrwx 10 Feb 6 18:32 net -> 'net:[4026532008]'lrwxrwxrwx 10 Feb 6 18:32 pid -> 'pid:[4026531836]'lrwxrwxrwx 10 Feb 6 18:32 pid_for_children -> 'pid:[4026531836]'lrwxrwxrwx 10 Feb 6 18:32 user -> 'user:[4026531837]'lrwxrwxrwx 10 Feb 6 18:32 uts -> 'uts:[4026531838]'
mnt namespace
Ввели в 2002 первым, ещё не знали, что понадобится много разных, потому обозвали флаг клонирования CLONE_NEWNS, что не соответствует флагам других namespaces.
С помощью mnt в Linux можно изолировать группу точек монтирования для групп процессов.
We have a successfully mounted tmpfs, which is not available on the host system level:
> ls mount-dir
> grep mount-dir /proc/mounts
The actual memory being used for the mount point is laying in an abstraction layer called Virtual File System (VFS), which is part of the kernel and where every other filesystem is based on.
Можно создавать на лету гибкие файловые системы. Mounts can have different flavors (shared, slave, private, unbindable), which is best explained within the shared subtree documentation of the Linux kernel.
uts namespace (UNIX Time-sharing System)
Ввели в 2006 в Linux 2.6.19. Можно отсоединить домен и имя хоста от системы.
And if we look at the system level nothing has changed, hooray:
exit> hostname
nb
ipc namespace
Ввели в 2006 в Linux 2.6.19. Можно изолировать связи между процессами. Например, общую память (shared memory = SHM) между процессами. Два процесса будут использовать 1 идентификатор для общей памяти, но при этом писать в 2 разных региона памяти.
pid namespace (Process ID)
Ввели в 2008 в Linux 2.6.24. Возможность для процессов иметь одинаковые PID в разных namespace. У одного процесса могут быть 2 PID: один внутри namespace, а второй вовне его - на хост системе. Можно делать вложенные namespace, и тогда PID у 1 процесса будет больше.
Первый процесс в namespace получается PID=1 и привилегии init-процесса.
> sudo unshare -fp --mount-proc
# ps aux
Флаг --mount-proc нужен чтобы переподключить proc filesystem из нового namespace. Иначе PID в namespace будут не видны.
net namespace (Network)
Ввели в 2009 в Linux 2.6.29 для виртуализации сетей. Каждая сеть имеет свои свойства в разделе /proc/net. При создании нового namespace он содержит только loopback интерфейсы. Создадим:
> sudo unshare -n
# ip l# ip a
Каждый интерфейс (физ или вирт) присутствует единожды в каждом namespace. Интерфейсы можно перемещать между namespace;
Каждый namespace имеет свой набор ip, таблицу маршрутизации, список сокетов, таблицу отслеживания соединений, МЭ и т.д. ресурсы;
Удаление net namespace разрушает все вирт интерфейсы и перемещает оттуда все физические.
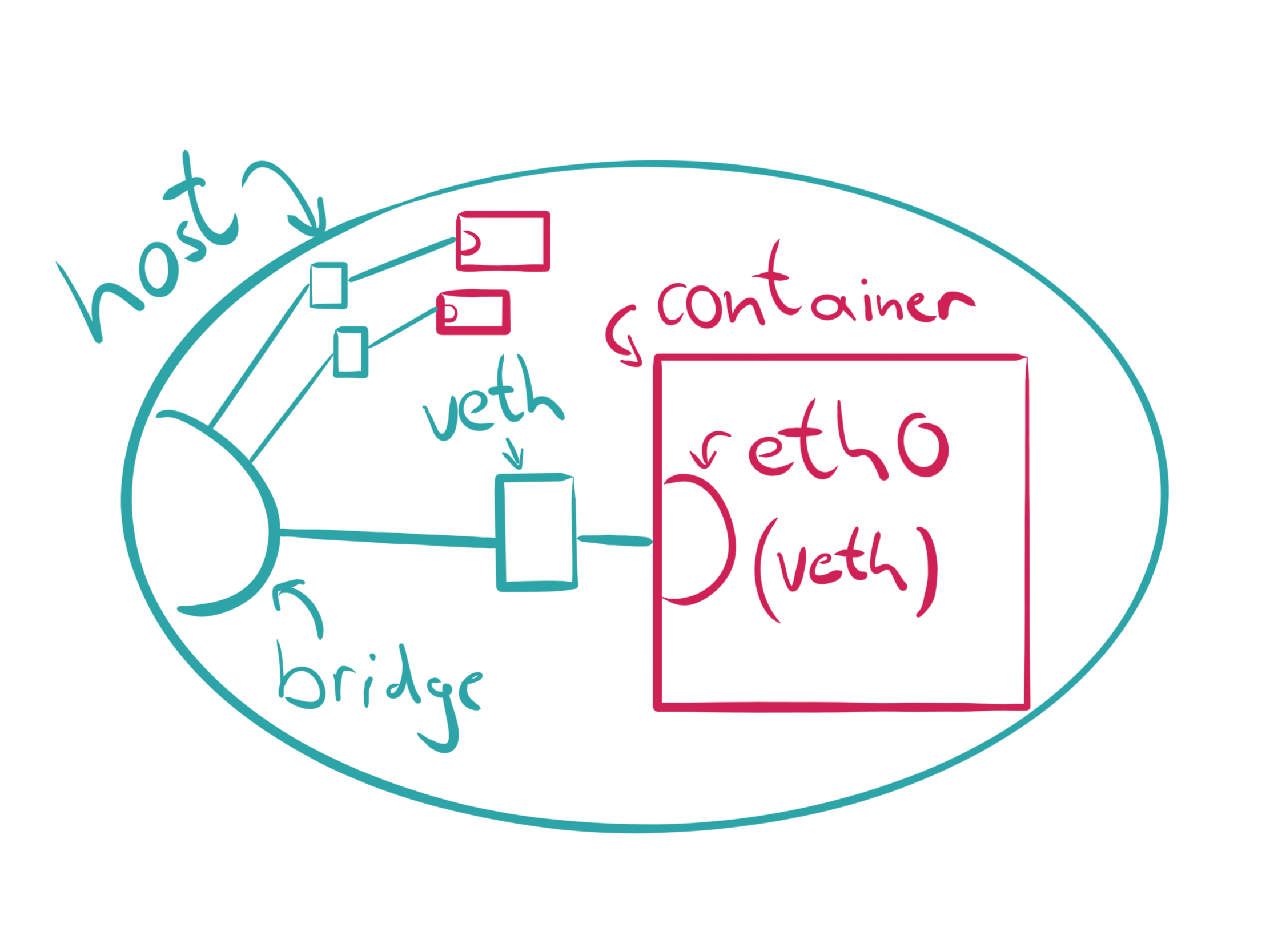
Применение: создание SDN через пары виртуальных интерфейсов. Один конец пары подключается к bridge, а другой конец - к целевому контейнеру. Так работают CNI типа Flannel.
Создадим новый net namepsace:
> sudo ip netns add mynet
> sudo ip netns list
mynet
Когда команда ip создаёт network namespace, она создаёт it will create a bind mount for it under /var/run/netns too. This allows the namespace to persist even when no processes are running within it.
> sudo ip netns exec mynet ip l
> sudo ip netns exec mynet ping 127.0.0.1
The network seems down, let’s bring it up:
> sudo ip netns exec mynet ip link set dev lo up
> sudo ip netns exec mynet ping 127.0.0.1
Let’s create a veth pair which should allow communication later on:
> sudo ip link add veth0 type veth peer name veth1
> sudo ip link show type veth
Both interfaces are automatically connected, which means that packets sent to veth0 will be received by veth1 and vice versa. Now we associate one end of the veth pair to our network namespace:
> sudo ip link set veth1 netns mynet
> ip link show type veth
Добавляем адреса ip:
> sudo ip netns exec mynet ip addr add 172.2.0.1/24 dev veth1
> sudo ip netns exec mynet ip link set dev veth1 up
> sudo ip addr add 172.2.0.2/24 dev veth0
> sudo ip link set dev veth0 up
It works, but we wouldn’t have any internet access from the network namespace. We would need a network bridge or something similar for that and a default route from the namespace.
user namespace
Ввели в 2012-2013 в Linux 3.5-3.8 для изоляции пользователей, групп пользователей.
Пользователь получает разные ID внутри и вовне namespace, а также разные привилегии.
> id -u
1000> unshare -U
> whoami
nobody
После создания namespace, файлы /proc/$PID/{u,g}id_map раскрывают соответствия user+groupID и PID. Эти файлы пишутся лишь единожды для определения соответствий.
> cat /proc/$PID/uid_map
010001
cgroups
Ввели в 2008 в Linux 2.6.24 для квотирования и далее переделали капитально в 2016 в Linux 4.6 - ввели cgroups namespace.
Система выдаёт список ограничений. Поменяем ограничения памяти для этой cgroup. Также отключим swap, чтобы реализация сработала:
unshare -c # unshare cgroupns in some cgroupcat /proc/self/cgroup
sudo mkdir /sys/fs/cgroup/demo
cd /sys/fs/cgroup/demo/
sudo su
echo100000000 > memory.max
echo0 > memory.swap.max
cat /proc/self/cgroup
echo0 > cgroup.procs
cat /proc/self/cgroup
После того как установлено ограничение в 100Mb памяти ОЗУ, напишем приложение, которое забирает память больше чем положенные 100Mb (в случае отсутствия ограничений приложение закрывается при занятии 200Mb):
fnmain(){letmutvec=vec![];letmax_switch: usize=20;// запасное ограничение =200Mb
letmutmemcount: usize;loop{vec.extend_from_slice(&[1u8;10_000_000]);memcount=vec.len()/10_000_000;println!("{}0 MB",memcount);ifmemcount>max_switch{break;}}println!("Program terminated by MAX MEM = {}0 Mb",memcount);}
Если его запустить, то увидим, что PID будет убит из-за ограничений памяти:
Можно составлять пространства имён вместе, чтобы они делили 1 сетевой интерфейс. Так работают k8s Pods. Создадим новое пространство имён с изолированным PID:
> sudo unshare -fp --mount-proc
# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.6 186886904 pts/0 S 23:36 0:00 -bash
root 39 0.0 0.1 354801836 pts/0 R+ 23:36 0:00 ps aux
Вызов ядра setns с приложением-обёрткой nsenter теперь можно использовать для присоединения к пространству имён. Для этого нужно понять, в какое пространство мы хотим присоединиться:
> exportPID=$(pgrep -u root bash)> sudo ls -l /proc/$PID/ns
В 2007 году Google сделали проект Let Me Contain That For You (LMCTFY), в 2008 году появился Linux Containers (LXC). Для управления LXC в 2013 году появился инструмент Docker. Далее в 2015, команда Docker разработали проект libcontainer на языке Go. Также, в 2015 вышел Kubernetes 1.0. В 2015 собрали Open Container Initiative (OCI), которые стали разрабатывать стандарты на метаданные (манифесты-спецификации), образы контейнеров, методы управления ими. В том числе, в рамках OCI создали инструмент запуска и работы с контейнерами runc.
runc
sudo apt install runc
runc spec
cat config.json
В спецификации от runc можно увидеть всё необходимое для создания и запуска контейнера: environment variables, user + group IDs, mount points, Linux namespaces. Не хватает только файловой системы (rootfs), базового образа контейнера:
В ней можно увидеть обычные поля из runc, а доп заполненные annotations:
"annotations":{"org.opencontainers.image.title":"openSUSE Tumbleweed Base Container","org.opencontainers.image.url":"https://www.opensuse.org/","org.opencontainers.image.vendor":"openSUSE Project","org.opencontainers.image.version":"20190517.6.190",
Чтобы создать контейнер с runc, нужно его зацепить на терминал ввода команд TTY:
sudo runc create -b bundle container
ERRO[0000] runc create failed: cannot allocate tty if runc will detach without setting console socket
На существующий TTY зацепить контейнер нельзя (потому что окно удалённого xTerm не поддерживает такое), нужно создать новый виртуальный TTY и указать его сокет. Для этого надо установить Golang, скачать приложение rectty, создать с его помощью виртуальный терминал, после чего В ДРУГОМ ОКНЕ терминала создать контейнер и зацепить его на создвнный TTY:
В ДРУГОМ ОКНЕ терминала создать контейнер и зацепить его на создвнный TTY:
sudo runc create -b bundle --console-socket $(pwd)/tty.sock container
sudo runc list # контейнер в статуса created, не запущенsudo runc ps container # посмотрим что внутри негоUID PID PPID C STIME TTY TIME CMD
root 2977210 10:35 ? 00:00:00 runc init
runc init создаёт новую среду со всеми namespaces. /bin/bash ещё не запущен в контейнере, но уже можно запускать в нём свои процессы, полезно чтоб настроить сеть:
sudo runc start container
sudo runc list
sudo runc ps container
UID PID PPID C STIME TTY TIME CMD
root 652165110 14:25 pts/0 00:00:00 /bin/bash
Исходный runc init пропал, теперь только /bin/bash существует в контейнере. На ПЕРВОМ ОКНЕ терминала появилась консоль контейнера:
$ ps aux
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 51564504 pts/0 Ss 10:28 0:00 /bin/bash
root 29 0.0 0.0 65283372 pts/0 R+ 10:32 0:00 ps aux
Можно проверить управление: заморозим контейнер. Во ВТОРОМ ОКНЕ терминала выполним:
sudo runc pause container
# в первом окне ввод команд прервётсяsudo runc resume container
# Рассмотрим события контейнера:sudo runc events container
#{...}
Для остановки контейнера достаточно выйти из rectty-сессии, после чего удалить контейнер. Остановленный контейнер нельзя перезапустить, можно лишь пересоздать в новом состоянии:
> sudo runc list
ID PID STATUS BUNDLE CREATED OWNER
container 0 stopped /bundle 2019-05-21T10:28:32.765888075Z root
> sudo runc delete container
> sudo runc list
ID PID STATUS BUNDLE CREATED OWNER
Можно модифицировать спецификацию в контейнере (bundle/config.json):
> sudo apt install moreutils, jq # инструмент jq для работы с JSON> cd bundle
> jq '.process.args = ["echo", "Hello, world!"]' config.json | sponge config.json
> sudo runc run container
> Hello, world!
Можно удалить разделение PID namespace процессов в контейнере с хостом:
> jq '.process.args = ["ps", "a"] | del(.linux.namespaces[0])' config.json | sponge config.json
> sudo runc run container
16583 ? S+ 0:00 sudo runc run container
16584 ? Sl+ 0:00 runc run container
16594 pts/0 Rs+ 0:00 ps a
[output truncated]
runc очень низкоуровневый и позволяет серьёзно нарушить работу и безопасность контейнеров.
Однако, их намного удобнее использовать на уровне управления выше
Для защиты также можно запускать контейнеры в режиме rootless из runc
С помощью runc нужно руками настраивать сетевые интерфейсы, очень трудоемко
CRI-O
Инструмент CRI-O разработан в 2016 при участии OCI в рамках проекта Kubernetes. Философия UNIX, максимально лёгкий аналог Docker/containerd. Он НЕ предназначен как инструмент для приёма команд от разработчиков. Задача - принимать команды от K8s. Внутри себя CRI-O использует runc как backend, и принимает команды по gRPC API как frontend.
Попробуем CRI-O с помощью спец-контейнера с crictl:
sudo apt install podman
sudo vim /etc/containers/registries.conf
# нужно задать репозиторий для скачивания:# unqualified-search-registries=["docker.io"] sudo podman run --privileged -h crio-playground -it saschagrunert/crio-playground