Kernel
External link:
chroot
- Впервые в Minix и UNIX Version 7 (released 1979)
- В Linux этот syscall - функция ядра kernel API function.
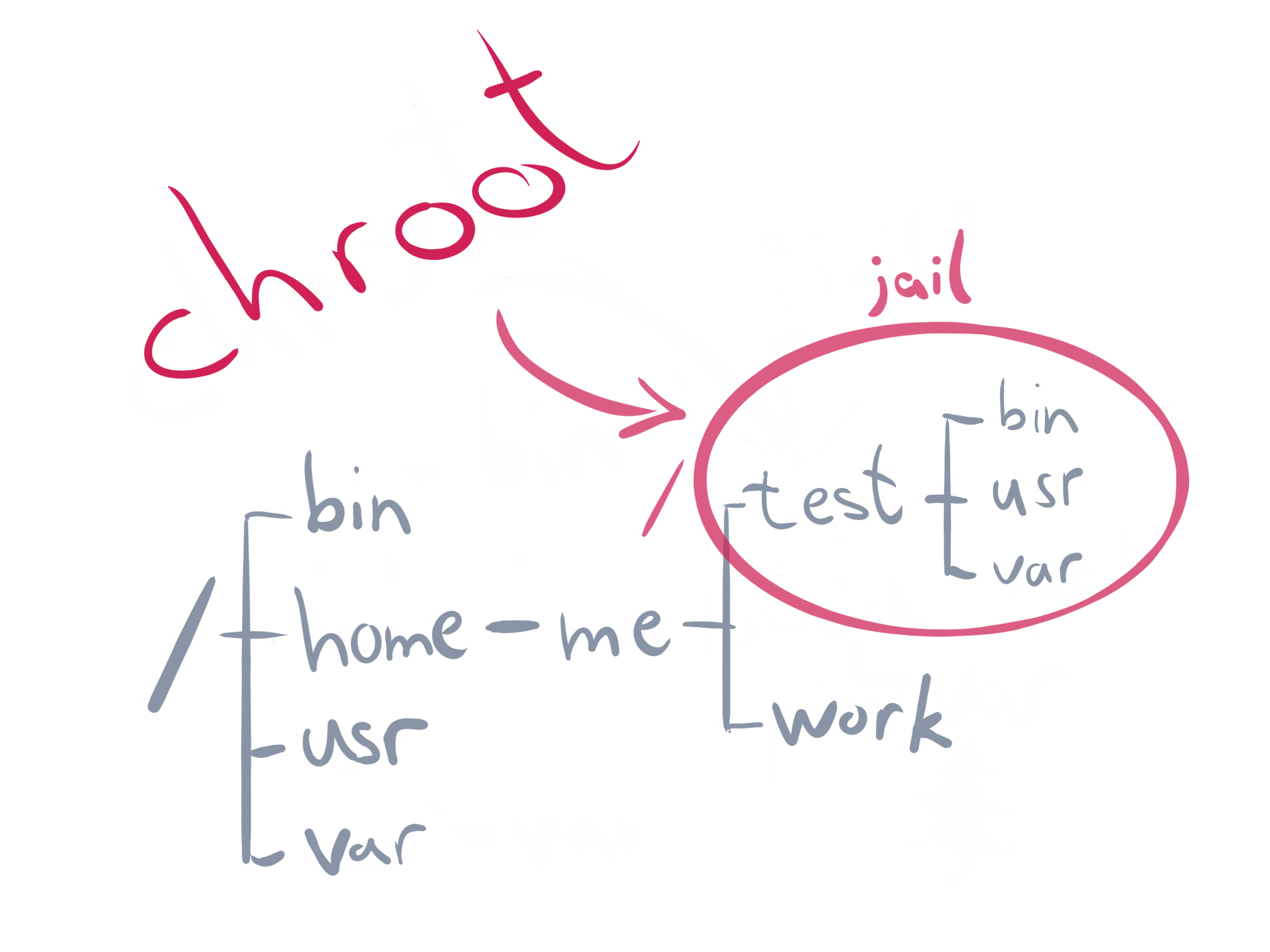 chroot - утилита, которая предназначена для изоляции файловой среды приложения. Создана в Minix 1.7. Для процессов и ОЗУ не подходит, но вдохновила создание Namespaces в Linux позднее.
chroot - утилита, которая предназначена для изоляции файловой среды приложения. Создана в Minix 1.7. Для процессов и ОЗУ не подходит, но вдохновила создание Namespaces в Linux позднее.
Пример работы
Для работы bash в новой среде chroot необходимо внести его копию в папку jail:
Далее нужно увидеть зависимости и перенести их:
Либо, гораздо проще перенести разом все библиотеки:
Далее, заход в окружение:
- Only privileged processes with the capability CAP_SYS_CHROOT are able to call chroot.
- Modern systems use pivot_mount (calling process must have the CAP_SYS_ADMIN capability). - has the benefit of putting the old mounts into a separate directory on calling.
Linux Namespaces
- Задача: обернуть системные ресурсы в уровень абстракции;
- Introduced in Linux 2.4.19 (2002), became “container ready” in 3.8 in 2013 with the introduction of the user namespace;
- Seven distinct namespaces implemented: mnt, pid, net, ipc, uts, user, cgroup; time and syslog introduced in 2016;
- функция clone . Создаёт дочерние процессы. Unlike
fork(2), theclone(2)API allows the child process to share parts of its execution context with the calling process, such as the memory space, the table of file descriptors, and the table of signal handlers. You can pass different namespace flags toclone(2)to create new namespaces for the child process.
unshare(2) - отсоединение частей контекста выполнения процесса.
setns(2) позволяет запрашивающему процессу присоединяться в разные namespaces.
proc - Besides the available syscalls, the proc filesystem populates additional namespace related files. Since Linux 3.8, each file in /proc/$PID/ns is a “magic“ link which can be used as a handle for performing operations (like setns(2)) to the referenced namespace.
mnt namespace
Ввели в 2002 первым, ещё не знали, что понадобится много разных, потому обозвали флаг клонирования CLONE_NEWNS, что не соответствует флагам других namespaces. С помощью mnt в Linux можно изолировать группу точек монтирования для групп процессов.
We have a successfully mounted tmpfs, which is not available on the host system level:
The actual memory being used for the mount point is laying in an abstraction layer called Virtual File System (VFS), which is part of the kernel and where every other filesystem is based on.
Можно создавать на лету гибкие файловые системы. Mounts can have different flavors (shared, slave, private, unbindable), which is best explained within the shared subtree documentation of the Linux kernel.
uts namespace (UNIX Time-sharing System)
Ввели в 2006 в Linux 2.6.19. Можно отсоединить домен и имя хоста от системы.
And if we look at the system level nothing has changed, hooray:
ipc namespace
Ввели в 2006 в Linux 2.6.19. Можно изолировать связи между процессами. Например, общую память (shared memory = SHM) между процессами. Два процесса будут использовать 1 идентификатор для общей памяти, но при этом писать в 2 разных региона памяти.
pid namespace (Process ID)
Ввели в 2008 в Linux 2.6.24. Возможность для процессов иметь одинаковые PID в разных namespace. У одного процесса могут быть 2 PID: один внутри namespace, а второй вовне его - на хост системе. Можно делать вложенные namespace, и тогда PID у 1 процесса будет больше. Первый процесс в namespace получается PID=1 и привилегии init-процесса.
Флаг --mount-proc нужен чтобы переподключить proc filesystem из нового namespace. Иначе PID в namespace будут не видны.
net namespace (Network)
Ввели в 2009 в Linux 2.6.29 для виртуализации сетей. Каждая сеть имеет свои свойства в разделе /proc/net. При создании нового namespace он содержит только loopback интерфейсы. Создадим:
- Каждый интерфейс (физ или вирт) присутствует единожды в каждом namespace. Интерфейсы можно перемещать между namespace;
- Каждый namespace имеет свой набор ip, таблицу маршрутизации, список сокетов, таблицу отслеживания соединений, МЭ и т.д. ресурсы;
- Удаление net namespace разрушает все вирт интерфейсы и перемещает оттуда все физические.
Применение: создание SDN через пары виртуальных интерфейсов. Один конец пары подключается к bridge, а другой конец - к целевому контейнеру. Так работают CNI типа Flannel.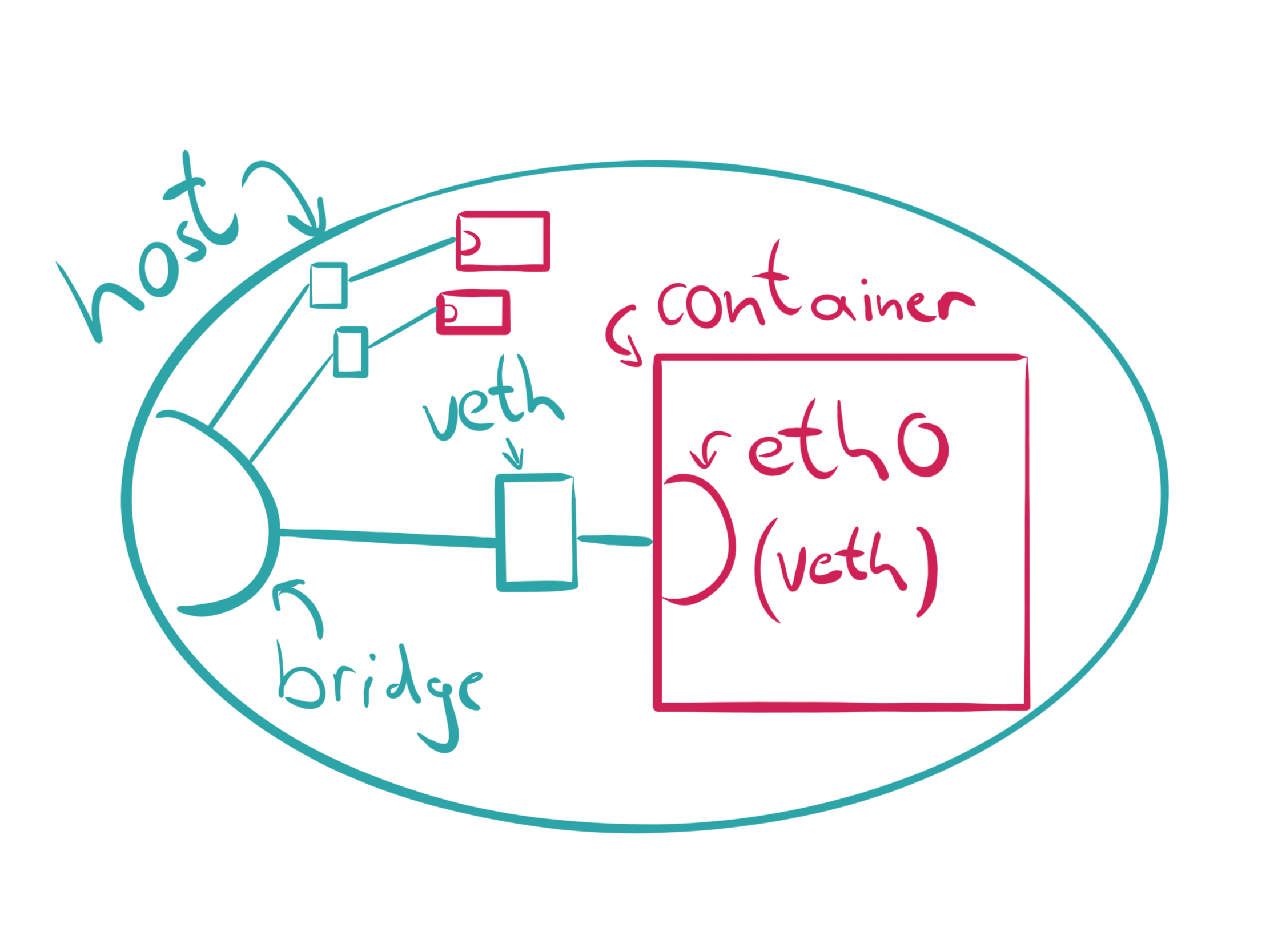 Создадим новый net namepsace:
Создадим новый net namepsace:
Когда команда ip создаёт network namespace, она создаёт it will create a bind mount for it under /var/run/netns too. This allows the namespace to persist even when no processes are running within it.
The network seems down, let’s bring it up:
Let’s create a veth pair which should allow communication later on:
Both interfaces are automatically connected, which means that packets sent to veth0 will be received by veth1 and vice versa. Now we associate one end of the veth pair to our network namespace:
Добавляем адреса ip:
Теперь можно связываться в обе стороны:
It works, but we wouldn’t have any internet access from the network namespace. We would need a network bridge or something similar for that and a default route from the namespace.
user namespace
Ввели в 2012-2013 в Linux 3.5-3.8 для изоляции пользователей, групп пользователей. Пользователь получает разные ID внутри и вовне namespace, а также разные привилегии.
После создания namespace, файлы /proc/$PID/{u,g}id_map раскрывают соответствия user+groupID и PID. Эти файлы пишутся лишь единожды для определения соответствий.
cgroups
Ввели в 2008 в Linux 2.6.24 для квотирования и далее переделали капитально в 2016 в Linux 4.6 - ввели cgroups namespace.
Cgroup version check:
For cgroup v2, the output is cgroup2fs.
For cgroup v1, the output is tmpfs.
cgroups memory limit
Cgroups memory.limit_in_bytes was deprecated because it is prone to race condition: https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#deprecated-v1-core-features
Использовать memory.max (in bytes)! https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#namespace
Система выдаёт список ограничений. Поменяем ограничения памяти для этой cgroup. Также отключим swap, чтобы реализация сработала:
После того как установлено ограничение в 100Mb памяти ОЗУ, напишем приложение, которое забирает память больше чем положенные 100Mb (в случае отсутствия ограничений приложение закрывается при занятии 200Mb):
Если его запустить, то увидим, что PID будет убит из-за ограничений памяти:
Составление пространств имен
Можно составлять пространства имён вместе, чтобы они делили 1 сетевой интерфейс. Так работают k8s Pods. Создадим новое пространство имён с изолированным PID:
Вызов ядра setns с приложением-обёрткой nsenter теперь можно использовать для присоединения к пространству имён. Для этого нужно понять, в какое пространство мы хотим присоединиться:
Теперь присоединяемся с помощью nsenter:
Своё приложение, создающее контейнер
https://brianshih1.github.io/mini-container/preface.html
runc
Система сборки и запуска контейнеров:
Можно исследовать, что runc создал mnt, uts, ipc, pid и net: