Можно поймать панику во всём тесте с помощью ключа #[should_panic]:
#[test]#[should_panic(expected = "assertion failed")]fntest_example(){letroom_nums=[1,2,3,4];letmax_length=room_nums.len();letindex_out_of_bounds=room_nums.get(max_length+1);assert!(index_out_of_bounds.is_some());// паника будет тут
}
❗Если паники по факту не будет, тест провалится.
Можно перехватить панику в конкретной команде с помощью std::panic::catch_unwind():
В библиотеках требуется получать на выходе конкретный тип ошибки, поэтому там применяется thiserror.
Установка
cargo add anyhow
Использование
Anyhow создаёт алиас наподобие Result<T> = Result<T, Box<dyn Error>>, чтобы скрыть тип ошибок и сделать его универсальным.
// ---- Без Anyhow
fnstring_error()-> Result<(),String>{Ok(())}fnio_error()-> Result<(),std::io::Error>{Ok(())}fnany_error()-> Result<(),Box<dynError>>{string_error()?;io_error()?;Ok(())}// ---- С Anyhow:
useanyhow::Result;fnstring_error()-> Result<()>{Ok(())}fnio_error()-> Result<()>{Ok(())}fnany_error()-> Result<()>{string_error()?;io_error()?;Ok(())}
Пример неудачного чтения файла:
useanyhow::{Context,Result};fnread_config_file(path: &str)-> Result<String>{std::fs::read_to_string(path).with_context(||format!("Failed to read file {}",path))}fnmain()-> Result<()>{letconfig_content=read_config_file("conf.txt")?;println!("Config content:\n{:?}",config_content);Ok(())}
Result<T> становится алиасом к Result<T, anyhow::Error>;
Context, with_context() позволяет добавить подробности к ошибке, в случае неуспеха функции чтения read_to_string();
Оператор ? выносит ошибку вверх, при этом авто-конвертирует её тип в anyhow::Error.
Замена Box<dyn> с контекстом
Возьмём пример, в котором чтение файла std::fs::read_to_string() (может быть неудачным), далее дешифровка его контента с помощью base64 decode() (может не получиться) в цепочку байт, из которой формируется строка String::from_utf8() (может не получиться). Все эти три потенциальных ошибки имеют разный тип.
Один способ все три их принять на одну функцию, это с помощью Box<dyn std::error::Error>>, потому что все 3 ошибки применяют std::error::Error.
Подход рабочий, но при срабатывании одной из трёх ошибок, судить о происхождении проблемы можно будет лишь по сообщению внутри ошибки.
В случае применения Anyhow, можно заменить им Box<dyn>, при этом сразу добавить контекстные сообщения, которое поможет понять место:
useanyhow::Context;usebase64::{self,engine,Engine};fndecode()-> Result<(),anyhow::Error>{letinput=std::fs::read_to_string("input").context("Failed to read file")?;// контекст 1
forlineininput.lines(){letbytes=engine::general_purpose::STANDARD.decode(line).context("Failed to decode the input")?;// контекст 2
println!("{}",String::from_utf8(bytes).context("Failed to cenvert bytes")?// контекст 3
);}Ok(())
Замена map_err()
map_err() - это универсальный метод из стандартной библиотеки, который работает с любым Result. context() - это метод из anyhow, специально созданный для удобного добавления контекста к ошибкам.
// map_err — нужно явно создавать anyhow::Error
.map_err(|e|anyhow::anyhow!("ошибка: {}",e))// context — просто добавляет пояснение
.context("ошибка")?
context() принимает замыкание (closure), которое выполняется только при ошибке. Это важно для ресурсоемких операций:
// context с замыканием — форматирование только при ошибке
letcontent=std::fs::read_to_string(path).with_context(||format!("не удалось прочитать файл {}",path))?;// map_err — форматирование всегда, даже при успехе
letcontent=std::fs::read_to_string(path).map_err(|e|anyhow::anyhow!("не удалось прочитать файл {}",path))?;
with_context() - вариант context() с ленивым вычислением, идеален для дорогих операций вроде форматирования строк.
При запуске данная программа требует 2 аргумента, притом второй обязательно числом.
Добавление описаний
Имя программы и версия вносятся отдельным признаком. Доп. поля описания вносятся с помощью спец. комментариев ///:
useclap::Parser;#[derive(Parser, Debug)]#[command(author = "Author Name", version, about)]/// A very simple CLI parser
structArgs{/// Text argument option
arg1: String,/// Number argument option
arg2: usize,}fnmain(){letargs=Args::parse();println!("{:?}",args)}
Добавка флагов
Флаги добавляем с помощью аннотации #[arg(short, long)] для короткого и длинного именования флага. Если у 2-х флагов одинаковая первая буква, можно указать вручную их короткую версию. Короткая версия не может быть String, можно только 1 char.
<..>structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(short = 'A', long)]/// Number argument option
arg2: usize,}<..>
Необязательные флаги
Для отметки аргумента как необязательного достаточно указать его тип как Option<тип> и в скобках исходный тип данных:
structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(short = 'A', long)]/// Number argument option
arg2: Option<usize>,}
Такой подход потребует обработать ситуацию, когда в arg2 ничего нет. Вместо так делать, можно указать значение по умолчанию:
structArgs{#[arg(short = 'a', long)]/// Text argument option
arg1: String,#[arg(default_value_t=usize::MAX, short = 'A', long)]/// Number argument option
arg2: usize,}
Теперь arg2 по умолчанию будет равен максимальному числу usize, если не указано иное.
Валидация введённых значений
В случае аргумента-строки есть возможность ввести пустую строку из пробелов " ". Для исключения таких вариантов, вводится функция валидации и её вызов:
useclap::Parser;#[derive(Parser, Debug)]#[command(author = "Author Name", version, about)]/// A very simple CLI parser
structArgs{#[arg(value_parser = validate_argument_name, short = 'a', long)]/// Text argument option
arg1: String,#[arg(default_value_t=usize::MAX, short = 'A', long)]/// Number argument option
arg2: usize,}fnvalidate_argument_name(name: &str)-> Result<String,String>{ifname.trim().len()!=name.len(){Err(String::from("строка не должна начинаться или заканчиваться пробелами",))}else{Ok(name.to_string())}}fnmain(){letargs=Args::parse();println!("{:?}",args)}
Теперь при попытке вызвать программу tiny-clapper -- -a " " будет показана ошибка валидации.
❗Ограничение - можно вызывать только существующие объекты, нельзя добавлять свой текст.
spawn - гибкий ввод
Самый гибкий вариант, позволяющий делать свой ввод, а не только существующие команды и файлы-папки, это через spawn:
letmutchild=Command::new("cat")// команда
.stdin(Stdio::piped()).stdout(Stdio::piped()).spawn()?;letstdin=child.stdin.as_mut()?;stdin.write_all(b"Hello Rust!\n")?;// текст к команде, /n обязателен
letoutput=child.wait_with_output()?;foriinoutput.stdout.iter(){// цикл на случай многострочного вывода
print!("{}",*iaschar);}Ok(())
❗Ограничение - можно подавать на вход текст лишь тем командам, которые требуют сразу указать вводный текст. При этом ряд команд делают паузу перед потреблением текста на вход, с такими свой ввод работать не будет это относится и к фильтрации через pipe = | grep <...> и аналоги.
Pipe (nightly) - полный ввод (не проверенный способ)
#![feature(anonymous_pipe)]// только в Rust Nightly
usestd::pipelettext="| grep file".as_bytes();// Запускаем саму команду
letchild=Command::new("ls").arg("/Users/test").stdin({// Нельзя отправить просто строку в команду
// Нужно создать файловый дескриптор (как в обычном stdin "pipe")
// Поэтому создаём пару pipes тут
let(reader,mutwriter)=std::pipe::pipe().unwrap();// Пишем строку в одну pipe
writer.write_all(text).unwrap();// далее превращаем вторую для передачи в команду сразу при spawn.
Stdio::from(reader)}).spawn()?;
Sorting() a string of letters (with rev() - reverse order)
useitertools::Itertools;lettext="Hello world";lettext_sorted=text.chars().sorted().rev().collect::<String>();// rev() - Iterate the iterable in reverse
println!("Text: {}, Sorted Text: {}",text,text_sorted);// Text: Hello world, Sorted Text: wroollledH
Counts() подсчёт количества одинаковых элементов в Array
useitertools::Itertools;letnumber_list=[1,12,3,1,5,2,7,8,7,8,2,3,12,7,7];letmode=number_list.iter().counts();// Itertools::counts()
// возвращает HashmapHashMap<char, usize>,
// где ключи взяты из массива, значения - частота
for(key,value)in&mode{println!("Число {key} встречается {value} раз");}
По сути counts() создаёт HashMap, заменяя собой конструкцию или конструкцию на базе fold():
userand::Rng;fnmain(){letsecret_of_type=rand::rng().random::<u32>();letsecret=rand::rng().random_range(1..=100);println!("Random nuber of type u32: {secret_of_type}");println!("Random nuber from 1 to 100: {}",secret);}
В старой версии библиотеки применялся признак gen(), который переименовали в связи с добавлением gen() в Rust 2024.
. any character except new line (includes new line with s flag)
\d digit (\p{Nd})
\D not digit
\pX Unicode character class identified by a one-letter name
\p{Greek} Unicode character class (general category or script)
\PX Negated Unicode character class identified by a one-letter name
\P{Greek} negated Unicode character class (general category or script)
Классы символов
[xyz] A character class matching either x, y or z (union).
[^xyz] A character class matching any character except x, y and z.
[a-z] A character class matching any character in range a-z.
[[:alpha:]] ASCII character class ([A-Za-z])
[[:^alpha:]] Negated ASCII character class ([^A-Za-z])
[x[^xyz]] Nested/grouping character class (matching any character except y and z)
[a-y&&xyz] Intersection (matching x or y)
[0-9&&[^4]] Subtraction using intersection and negation (matching 0-9 except 4)
[0-9--4] Direct subtraction (matching 0-9 except 4)
[a-g~~b-h] Symmetric difference (matching `a` and `h` only)
[\[\]] Escaping in character classes (matching [ or ])
Совмещения символов
xy concatenation (x followed by y)
x|y alternation (x or y, prefer x)
Повторы символов
x* zero or more of x (greedy)
x+ one or more of x (greedy)
x? zero or one of x (greedy)
x*? zero or more of x (ungreedy/lazy)
x+? one or more of x (ungreedy/lazy)
x?? zero or one of x (ungreedy/lazy)
x{n,m} at least n x and at most m x (greedy)
x{n,} at least n x (greedy)
x{n} exactly n x
x{n,m}? at least n x and at most m x (ungreedy/lazy)
x{n,}? at least n x (ungreedy/lazy)
x{n}? exactly n x
Пустые символы
^ the beginning of text (or start-of-line with multi-line mode)
$ the end of text (or end-of-line with multi-line mode)
\A only the beginning of text (even with multi-line mode enabled)
\z only the end of text (even with multi-line mode enabled)
\b a Unicode word boundary (\w on one side and \W, \A, or \z on other)
\B not a Unicode word boundary
Группировка и флаги
(exp) numbered capture group (indexed by opening parenthesis)
(?P<name>exp) named (also numbered) capture group (names must be alpha-numeric)
(?<name>exp) named (also numbered) capture group (names must be alpha-numeric)
(?:exp) non-capturing group
(?flags) set flags within current group
(?flags:exp) set flags for exp (non-capturing)
Спец-символы
\* literal *, works for any punctuation character: \.+*?()|[]{}^$
\a bell (\x07)
\f form feed (\x0C)
\t horizontal tab
\n new line
\r carriage return
\v vertical tab (\x0B)
\123 octal character code (up to three digits) (when enabled)
\x7F hex character code (exactly two digits)
\x{10FFFF} any hex character code corresponding to a Unicode code point
\u007F hex character code (exactly four digits)
\u{7F} any hex character code corresponding to a Unicode code point
\U0000007F hex character code (exactly eight digits)
\U{7F} any hex character code corresponding to a Unicode code point
Первое совпадение будет иметь тип Option<match>, а в случае отсутствия совпадений = None.
Поиск всех совпадений
letpattern=regex::Regex::new(r"hello, (world|universe)!")?;letinput="hello, world! hello, universe!";letmatches: Vec<_>=pattern.find_iter(input).collect();// find_iter()
matches.iter().for_each(|i|println!("{}",i.as_str()));// matches = Vec<match> и содержит все совпадения
Add serde framework with Derive feature to use it in structures and functions. Also add a separate serde_json lib for converting into specifically JSON:
cargo add serde -F derive
cargo add serde_json
Usage
Add serde, then mark the structures with Serialise, Deserialise traits and use serde_json for serialising:
useserde::{Deserialize,Serialize};#[derive(PartialEq, Debug, Clone, Serialize, Deserialize)]pubenumLoginRole{Admin,User,}#[derive(Debug, Clone, Serialize, Deserialize)]pubstructUser{pubusername: String,pubpassword: String,pubrole: LoginRole,}pubfnget_default_users()-> HashMap<String,User>{letmutusers=HashMap::new();users.insert("admin".to_string(),User::new("admin","password",LoginRole::Admin),);users.insert("bob".to_string(),User::new("bob","password",LoginRole::User),);users}pubfnget_users()-> HashMap<String,User>{letusers_path=Path::new("users.json");ifusers_path.exists(){// Load the file!
letusers_json=std::fs::read_to_string(users_path).unwrap();letusers: HashMap<String,User>=serde_json::from_str(&users_json).unwrap();users}else{// Create a file and return it
letusers=get_default_users();letusers_json=serde_json::to_string(&users).unwrap();std::fs::write(users_path,users_json).unwrap();users}
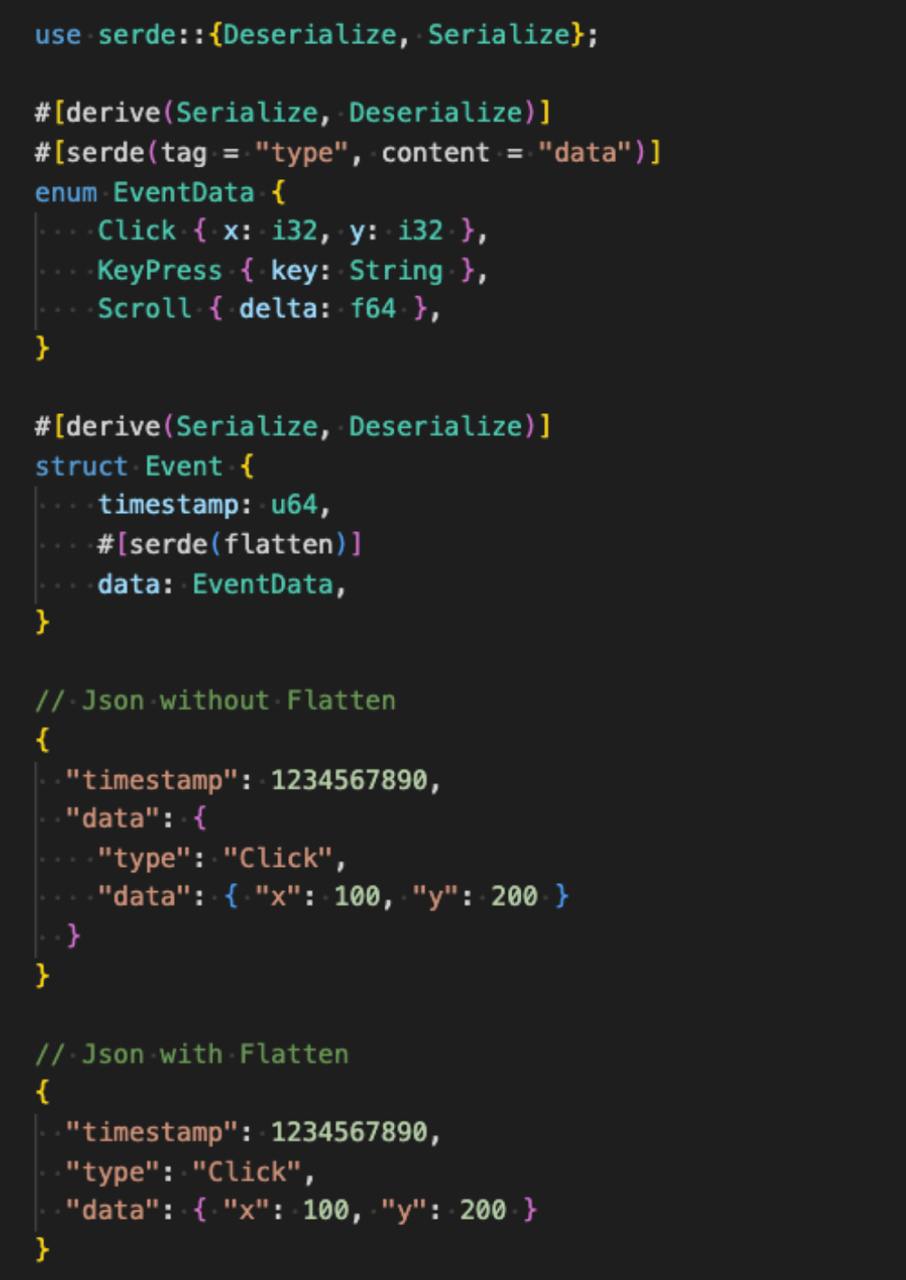
Flatten
Если при сериализации в JSON вы хотите, чтобы вложенные структуры или enum выглядели как часть общего объекта, используйте атрибут #[serde(flatten)]
Он убирает лишние уровни вложенности и делает JSON более читаемым и удобным:
usestd::process;// номер процесса PID вывести
usesysinfo::{RefreshKind,System};fnmain(){let_sys=System::new_with_specifics(RefreshKind::nothing());letpid=process::id();println!("System name: {:?}",System::name());println!("System kernel version: {:?}",System::kernel_version());println!("System OS version: {:?}",System::os_version());println!("System host name: {:?}",System::host_name());println!("Process ID: {}",pid);}
С помощью RefreshKind::nothing() отключаются все динамические вещи, такие как остаток свободной памяти, загрузка ЦПУ, сеть и так далее, что драматически ускоряет опрос системы.
Можно частично опрашивать разные системные ресурсы, по заданным интервалам.
usethiserror::Error;#[derive(Error, Debug)]pubenumMyLibError{#[error("Network failed: {0}")]Network(String),#[error("Invalid user ID: {id}")]InvalidUserId{id: u32},#[error("File not found")]NotFound,#[error("IO error: {0}")]Io(#[from]std::io::Error),}
#[from] в Io означает ? превращает std::io::Error в MyLibError::Io(...).
Все функции библиотеки возвращают Result с ошибкой в MyLibError:
pubfnget_user(id: u32)-> Result<String,MyLibError>{ifid==0{returnErr(MyLibError::InvalidUserId{id});}std::fs::read_to_string("config.txt")?;// автоконвертирует тип ошибки
Ok(format!("User {}",id))}
Особенность применения:
Для работы с ошибками в БИБЛИОТЕКАХ (libs)!
В приложениях проще унифицировать тип ошибки, поэтому там применяется anyhow.
Пользователи библиотеки могут проверять по конкретным ошибкам:
useyour_lib::{get_user,MyLibError};matchget_user(0){Ok(name)=>println!("Got {name}"),Err(MyLibError::InvalidUserId{id})=>{println!("You gave ID {id}, but that's invalid!");// обработать конкретно
}Err(MyLibError::NotFound)=>{println!("File missing, creating new one...");// создать файл
}Err(e)=>{println!("Other error: {e}");}}
В случае с anyhow, пользователи получили бы единый тип anyhow::Error и вынуждены были бы парсить строки (плохой код).
Пример применения:
// Библиотека (image_loader.rs)
#[derive(thiserror::Error, Debug)]pubenumImageError{#[error("File too large: {size} bytes")]TooLarge{size: u64},#[error("Unsupported format: {format}")]BadFormat{format: String},#[error("Corrupted data")]Corrupted,}pubfnload_image(path: &str)-> Result<Vec<u8>,ImageError>{// ...
}// Кто-то используем библиотеку:
matchimage_loader::load_image("photo.png"){Ok(data)=>render(data),Err(ImageError::TooLarge{size})=>println!("Your image is {size} bytes, max is 10MB"),Err(ImageError::BadFormat{format})=>println!("Sorry, we don't support {format} files"),Err(ImageError::Corrupted)=>println!("The image is broken"),}
Наблюдаемость позволяет понять систему извне, задавая вопросы о ней, при этом не зная ее внутреннего устройства. Кроме того, она позволяет легко устранять неполадки и решать новые проблемы, то есть «неизвестные неизвестные». Она также поможет вам ответить на вопрос «почему что-то происходит?».
Чтобы задать эти вопросы о вашей системе, приложение должно содержать полный набор инструментов. То есть код приложения должен отправлять сигналы, такие как трассировки, метрики и журналы. Приложение правильно инструментировано, когда разработчикам не нужно добавлять дополнительные инструменты для устранения неполадок, потому что у них есть вся необходимая информация.
Терминология
Событие журнала (Log event/message) - событие, произошедшее в конкретный момент времени;
Промежуток (Span record) - запись потока исполнения в системе за период времени. Он также выполняет функции контекста для событий журнала и родителя для под-промежутков;
Трасса (trace) - полная запись потока исполнения в системе от получения запроса до отправки ответа. Это по сути промежуток-родитель, или корневой промежуток;
Подписчик (subscriber) - реализует способ сбора данных трассы, например, запись их в стандартный вывод;
Контекст трассировки (Tracing Context): набор значений, которые будут передаваться между службами
usetracing::info;fnmain(){// Установка глобального сборщика по конфигурации
tracing_subscriber::fmt::init();letnumber_of_yaks=3;// новое событие, вне промежутков
info!(number_of_yaks,"preparing to shave yaks");}
Ручная инициализация свойств подписчика для форматирования лога:
fnsetup_tracing(){letsubscriber=tracing_subscriber::fmt().json()// нужно cargo add tracing-subscriber -F json
.with_max_level(tracing::Level::TRACE)// МАХ уровень логирования
.compact()// компактный лог
.with_file(true)// показывать файл-исходник
.with_line_number(true)// показать номера строк кода
.with_thread_ids(true)// показать ID потока с событием
.with_target(false)// не показывать цель (модуль) события
.finish();tracing::subscriber::set_global_default(subscriber).unwrap();tracing::info!("Starting up");tracing::warn!("Are you sure this is a good idea?");tracing::error!("This is an error!");}
Макрос #[instrument] автоматически создаёт промежутки (spans) для функций, а подписчик (subscriber) настроен выводить промежутки в stdout.
Трассировка потоков в асинхронном режиме
usetracing_subscriber::fmt::format::FmtSpan;#[tracing::instrument]// инструмент следит за временем работы
asyncfnhello(){tokio::time::sleep(tokio::time::Duration::from_secs(1)).await;}#[tokio::main]// cargo add tokio -F time,macros,rt-multi-thread
asyncfnmain()-> anyhow::Result<()>{letsubscriber=tracing_subscriber::fmt().json().compact().with_file(true).with_line_number(true).with_thread_ids(true).with_target(false).with_span_events(FmtSpan::ENTER|FmtSpan::CLOSE)// вход и выход
.finish();// потока отслеживать
tracing::subscriber::set_global_default(subscriber).unwrap();hello().await;Ok(())}
В итоге получаем лог работы потока с временем задержки:
2024-12-24T14:30:17.378906Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383596Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383653Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"enter"}{}2024-12-24T14:30:18.383675Z INFO ThreadId(01) hello: src/main.rs:3: {"message":"close","time.busy":"179µs","time.idle":"1.00s"}{}
Для записи журнала применяется отдельный модуль tracing-appender:
cargo add tracing-appender
У него много функций не только записи в облачные службы типа Datadog, но и создание журнала с дозаписью (минутной, часовой, дневной), а также запись как неблокирующее действие во время многопоточного исполнения.
Пример инициализации неблокирующей записи журнала в файл (лучше всего как JSON), одновременно вывод на экран и организация часового журнала с дозаписью (rolling):
usetracing::{instrument,warn};// тянем std::io::Write признак в режиме неблокирования
usetracing_subscriber::fmt::writer::MakeWriterExt;fnsetup_tracing(){// инициализация файла с дозаписью
letlogfile=tracing_appender::rolling::hourly("/some/directory","app-log");// уровень записи при логировании = INFO
letstdout=std::io::stdout.with_max_level(tracing::Level::INFO);letsubscriber=tracing_subscriber::fmt().with_max_level(tracing::Level::TRACE).json().compact().with_file(true).with_line_number(true).with_thread_ids(true).with_target(false).with_writer(stdout.and(logfile))// обязательно указать запись тут
.finish();// в файл и в stdout консоль
tracing::subscriber::set_global_default(subscriber).unwrap();}#[instrument]fnsync_tracing(){warn!("event 1");sync_tracing_sub();}#[instrument]fnsync_tracing_sub(){warn!("event 2");}fnmain(){setup_tracing();sync_tracing();}
Инициализация единого трассировщика на проекте
В составе Workspace трассировщик следует инициализировать единожды и далее использовать во всём проекте.
Для этого на верхнем уровне Workspace в Cargo.toml вписываем зависимость с применением по всему Workspace:
usecommon_log::setup_tracing;usetracing::{debug,error,info,warn};fnmain(){setup_tracing();// инициализация логгера из библиотеки common-log
info!("Logger initialized. App started.");// вызов логгера
}
Лог будет сохранён в папке /log/ в бинарном крейте, так как из него делается вызов инициализации.
Использование в тестах
#[cfg(test)]modtests{usesuper::*;usecommon_logging::setup_tracking;#[test]fntest_something(){init_test_logger();// ваш тест
}}
Настройка через переменные окружения
# Установка уровня логированияRUST_LOG=debug cargo run
RUST_LOG=my_library=debug,info cargo run
# Для конкретного крейтаRUST_LOG=my_library=debug cargo run
command - команда и параметры
watch - отслеживаемая папка
need_stdout - stdout вывод кода показывать к терминале
Далее запуск секции:
bacon check-examples
Интерактивный перезапуск компиляции
This will compile+build the code in examples folder, file “variables.rs”. Very convenient to try test different stuff. For live development do:
bacon run -- -q # сборка и запуск текущего проектbacon run -- -q --example <файл> # сборка и запуск файла в папке examplesbacon test# запуск unit-тестов (например, определённых для lib.rs)
cargo new test_project // create project with binary file src/main.rs
// OR
cargo new test_project --lib // create project with library file src/lib.rs
cd test_project
Source code is in src folder.
cargo build # build project for debug, do not runcargo run # build & run projectcargo check # fast compilingcargo build --release # slow build with optimizations for speed of release version
Documentation of methods & traits used in code can be compiled an opened in browser with Cargo command:
cargo doc --open
Зависимости кода в cargo.toml
[dependencies] — Package library dependencies - видно отовсюду, из тестов;
[dev-dependencies] — Dependencies for examples, tests, and benchmarks. При сборке ПО видны только для тестов (в рамках #[cfg(test)] mod tests {});
[build-dependencies] — Dependencies for build scripts.
Сборка бинарных файлов
Можно в src папке создать подпапку bin, и там сложить вариации бинарных файлов. После чего указывать при сборке cargo run --bin <название файла в папке bin>
Сборка Examples
Create “examples” folder beside the “src” folder. Create a file named, for example, “variables.rs” and place some test code in the folder. Then in the project root folder run:
cargo run --example variables
❗Примеры в Examples папке наследуют features и прочие параметры из общего Cargo.toml. В случае условной компиляции (см, далее) команда будет выглядеть: cargo run --example variables --features mock
Условная компиляция
Позволяет исключить часть кода в зависимости от условий.
#[cfg(feature = "debug")]// код сработает только с флагом debug
fnget_data()-> String{"мулька".to_string()}#[cfg(feature = "mock", feature = "debug")]// код сработает только с флагами mock И debug
fnget_data()-> String{"хитрая мулька".to_string()}#[cfg(not(feature = "debug"))]// код сработает без флага debug
fnget_data()-> String{"реальные данные".to_string()}fnmain(){println!("{}",get_data());}
Features нужно специально включать при сборке командой cargo run --features debug. Либо можно прописать флаг включения default = ["debug"] в файле Cargo.toml:
[features]default=["debug"]# по-умолчанию флаг = ВКЛdebug=[]
Отключить работу флага default можно командой cargo run --no-default-features.
Условная компиляция, встроенная в Cargo, позволяет подключать зависимости опционально. Можно проверять фичи в коде:
Пример с подключением библиотеки rand только для создания случайного значения в “mock-варианте” кода:
[features]default=["mock"]# включить флаг mock по-умолчаниюmock=["rand"]# использовать рандимозатор только при включенном флагеmock-persistent=["rand"][dependencies]rand={version="0.10.0",optional=true}# опциональный рандомизатор
Диагностика сборки
cargo-bloat для поиска проблем
cargo install cargo-bloat
cargo bloat --release
Определяет, какие зависимости задерживают сборку.
cargo build –timings
Создаёт отчёт в HTML с указанием трат времени:
cargo build --timings
# далее открыть target/cargo-timings/cargo-timing.html
cargo-llvm-lines
Показывает, какие generic-функции создают больше всего нагрузки для LLVM:
Generics создают мономорфизм - каждый новый тип создаёт новый код при сборке.
Ускорение сборки
Профили Cargo
Можно управлять ходом сборки проекта с помощью профилей. В том числе это сильно виляет на скорость сборки. Примеры профилей, которые можно создать в cargo.toml файле:
[profile.dev]opt-level=0# No optimization (fastest compilation LLVM)debug=1# Line info only (not full debug symbols)codegen-units=256# More parallelism (max is 256)incremental=true# Recompile only changed code[profile.release]opt-level=3# Maximum runtime performancelto="thin"# Faster than "fat" LTO, still good optimizationcodegen-units=1# Better optimization at cost of compile time
Для debug сборок, opt-level = 0 и высокое число codegen-units даю самую высокую скорость сборки (разница в скорости в 108 раз!).
Кеширование сборки зависимостей
С помощью sccache можно кешировать собранные артефакты, в том числе таскать кеш между системами.
Использовать все ядра, кроме 2 (чтобы ОС не повисла):
cargo build -j $(nproc --ignore=2)
Либо указать в .cargo/config.toml:
[build]jobs=8
Panic Response
В ответ на панику, по умолчанию программа разматывает стек (unwinding) - проходит по стеку и вычищает данные всех функций. Для уменьшения размера можно просто отключать программу без очистки - abort. Для этого в файле Cargo.toml надо добавить в разделы [profile]:
[profile.release]panic='abort'
Mold (только для Linux)
Проект для Linux (в macOS есть коммерческий аналог Sold, который ненамного лучше сборщику в XCode 15+, потому использование не оправдано).
Настройка
Ubuntu: sudo apt-get install mold clang
Fedora: sudo dnf install mold clang
Arch Linux: sudo pacman -S mold clang
Создать в проекте папку и файл .cargo/config.toml (либо для всех проектов сразу - папка и файл ~/.cargo/config.toml) и вписать:
Далее, в код бинарной программы включить функции из библиотеки:
useexamplelib::function01;// фукнкция должна быть публичной (pub fn)
Единая инициализация и сборка библиотек зависимостей в Workspace
Создаём проект типа workspace и прописываем в его файле Cargo.toml верхнего уровня все библиотеки с версиями (в примере anyhow) в спец разделе [workspace.dependencies]:
При этом в отдельном разделе [dependencies] указываем, что библиотеки будут распространяться на весь проект. Далее, создаём модуль внутри workspace (в примере = greeter) и в его файле Cargo.toml прописываем, что библиотека берётся из зависимостей workspace:
[dependencies]anyhow={workspace=true}
Можно добавлять features к библиотеке из workspace на этапе описания вложенных модулей:
Cargo audit - это инструмент, который проверяет зависимости проекта на наличие известных уязвимостей. Он не запускает код, не генерирует тесты и не следит за памятью. Вместо этого он сверяет версии всех библиотек (crates) с базой данных уязвимостей (RustSec Advisory Database).
Установка и запуск
cargo install cargo-audit # установить один разcargo audit # проверить проект
Пример вывода:
Crate:regexVersion:1.4.0Title:Regex panic on crafted inputSeverity:highSolution:upgrade to >= 1.5.0
Cargo audit находит только те проблемы, о которых кто-то сообщил и добавил в базу. Он не ищет новые, неизвестные уязвимости.
Какие проблемы находит Cargo Audit?
Тип уязвимости
Пример
Паника при специальном вводе
Библиотека крашится на строке вида “aaaaaaaa…”
Утечка данных
Библиотека отправляет данные на левый сервер
Проблемы с безопасностью
В версии 1.2.3 веб-сервера есть дыра для DoS-атаки
name:Rust CI/CD Pipelineon:push:branches:["main"]pull_request:branches:["main"]env:CARGO_TERM_COLOR:alwaysRUST_BACKTRACE:1jobs:# Job 1: Format and Lintformat-lint:runs-on:ubuntu-lateststeps:- uses:actions/checkout@v4- uses:actions-rs/toolchain@v1with:toolchain:nightlycomponents:rustfmt, clippyoverride:true- name:Format checkrun:cargo +nightly fmt -- --check- name:Clippyrun:>- cargo clippy --all-targets --all-features --workspace
-- -D warnings# Job 2: Build (original)build:runs-on:ubuntu-lateststeps:- uses:actions/checkout@v4- uses:actions-rs/toolchain@v1with:toolchain:stableoverride:true- name:Build releaserun:cargo build --release- name:Upload artifactsuses:actions/upload-artifact@v4with:name:binarypath:target/release/smarthouse# NEW JOB 3: Security Audit (Cargo Audit)# Checks if any dependencies have known vulnerabilitiessecurity-audit:runs-on:ubuntu-lateststeps:- uses:actions/checkout@v4# Install and run cargo-audit- name:Install cargo-auditrun:cargo install cargo-audit- name:Run security auditrun:cargo audit# This will fail the build if any vulnerabilities found# Exit code 1 if vulnerabilities detected# NEW JOB 4: Property-based Testing (Proptest)# Runs extended tests with randomly generated dataproptest:runs-on:ubuntu-lateststeps:- uses:actions/checkout@v4- uses:actions-rs/toolchain@v1with:toolchain:stableoverride:true# Run tests including proptest (slower than regular tests)- name:Run property-based testsrun:cargo test --release --lib -- --include-ignored proptest# --include-ignored runs proptest tests marked with #[ignore]# Proptest generates thousands of random inputs to find edge cases# Alternative: Run all tests with proptest enabled (no ignore)- name:Run all tests including proptest (alternative)run:cargo test --release -- --nocapture# This runs ALL tests, including proptest tests# Remove this if you prefer the filtered version above# NEW JOB 5: Unsafe Code Verification (Miri)# Checks for Undefined Behavior in unsafe Rust code# WARNING: Miri is VERY slow (100-1000x) but catches critical bugsmiri-check:runs-on:ubuntu-latest# Only run if you actually have unsafe code# Add a condition to avoid slow checks on simple projectssteps:- uses:actions/checkout@v4- uses:actions-rs/toolchain@v1with:toolchain:nightly # Miri requires nightly Rustcomponents:mirioverride:true# Install Miri component- name:Install Mirirun:| rustup +nightly component add miri
cargo +nightly miri setup# Run Miri on tests (catches UB in unsafe code)- name:Run Miri on testsrun:cargo +nightly miri test# This will find:# - Invalid memory access# - Data races in unsafe code# - Violations of Rust's aliasing rules# - Using uninitialized memory# Optional: Run Miri on the main binary- name:Run Miri on binary (optional)run:cargo +nightly miri run# Check if the main program has UBcontinue-on-error:true# Don't fail the build if this fails# Miri is extremely slow, so this might timeout in CI# NEW JOB 6: Memory Analysis (Valgrind)# Finds memory leaks and invalid memory access in compiled binary# NOTE: Only useful if you have C/C++ dependencies or complex unsafe codevalgrind-check:runs-on:ubuntu-latest# Only run on main branch (Valgrind is slow)if:github.ref == 'refs/heads/main'steps:- uses:actions/checkout@v4- uses:actions-rs/toolchain@v1with:toolchain:stableoverride:true# Build with debug symbols for better Valgrind output- name:Build with debug symbolsrun:cargo build# Install Valgrind- name:Install Valgrindrun:sudo apt-get update && sudo apt-get install -y valgrind# Run Valgrind on tests- name:Run Valgrind memory checkrun:| # Run each test binary through Valgrind
for test in target/debug/deps/*; do
if [ -x "$test" ] && [ ! -d "$test" ]; then
valgrind --leak-check=full \
--error-exitcode=1 \
--suppressions=valgrind.supp \
"$test" 2>&1 | tee -a valgrind.log
fi
done# This finds:# - Memory leaks (Rust usually doesn't have them)# - Invalid reads/writes in C/C++ dependencies# - Use of uninitialized memorycontinue-on-error:true# Don't fail the whole pipeline# Alternative: Run just the main binary- name:Run Valgrind on main binary (alternative)run:| valgrind --leak-check=full \
--error-exitcode=1 \
target/debug/smarthouse# Replace 'smarthouse' with your actual binary namecontinue-on-error:true# NEW JOB 7: Coverage Report (Optional)# Shows which parts of code are tested (complements Miri/Proptest)coverage:runs-on:ubuntu-lateststeps:- uses:actions/checkout@v4- name:Install cargo-tarpaulinrun:cargo install cargo-tarpaulin- name:Generate coverage reportrun:cargo tarpaulin --out Html --output-dir ./coverage- name:Upload coverage reportuses:actions/upload-artifact@v4with:name:coverage-reportpath:./coverage
Оптимизация CI для скорости
# Only run expensive jobs when unsafe code changesmiri-check:if:contains(github.event.pull_request.labels.*.name, 'unsafe-changes')# Cache dependencies to speed up builds- name:Cache cargo registryuses:actions/cache@v3with:path:~/.cargo/registrykey:${{ runner.os }}-cargo-${{ hashFiles('**/Cargo.lock') }}
Miri - это интерпретатор, который запускает код внутри особой безопасной песочницы. Miri даже не компилирует твою программу в реальный код. Он берёт твой Rust код и интерпретирует, проверяя:
Правила заимствования (одна ссылка на запись или много на чтение)
Выход за границы массива
Использование после перемещения
Miri понимает Rust: он знает, что такое &mut и почему два &mut на один объект — это плохо. Valgrind этого не поймёт. Miri замедляет работу кода в 100-1000х раз.
Valgrind запускает уже готовую скомпилированную программу и следит за ней со стороны:
Куда она обращается к памяти
Не забыла ли освободить то, что взяла
Не читает ли то, что уже удалила
Valgrind не знает правил Rust: он видит просто машинный код. Поэтому он может найти многие ошибки, но не понимает высокоуровневые концепции вроде заимствования или времени жизни. При этом Valgrind поддерживает проекты с миксом из Rust и C++ и т.д. языками. Valgrind замедляет работу кода в 20-50х раз.
Установка и запуск
Miri работает только в Nightly-версии Rust:
rustup toolchain install nightly
rustup +nightly component add miri
cargo +nightly miri testvalgrind ./my_program # программу уже скомпилировали
Проверка
Возьмём код с проблемами:
usestd::alloc::{alloc,dealloc,Layout};// BUG 1: Use-after-free (we'll read memory after freeing it)
fnuse_after_free()-> u8{letlayout=Layout::new::<u8>();letptr=unsafe{alloc(layout)};// Write something
unsafe{*ptr=42;}// Free the memory
unsafe{dealloc(ptr,layout);}// BUG: Reading after free! This is undefined behavior.
letvalue=unsafe{*ptr};value}// BUG 2: Memory leak (allocate but never free)
fnmemory_leak()-> *mutu8{letlayout=Layout::new::<u8>();letptr=unsafe{alloc(layout)};unsafe{*ptr=99;}// BUG: We never call dealloc! The memory leaks.
ptr}// BUG 3: Miri-specific - violating Rust's aliasing rules
fnaliasing_violation(){letmutx=5;letraw_ptr=&mutxas*muti32;// Create a second mutable pointer to the same memory
letraw_ptr2=&mutxas*muti32;unsafe{// Miri catches this: two mutable references to same data in scope
*raw_ptr=10;*raw_ptr2=20;// Undefined behavior per Rust's Stacked Borrows rules
}}fnmain(){println!("Testing use-after-free...");letval=use_after_free();println!("Read value: {} (this might be garbage)",val);println!("\nLeaking memory...");let_leaked=memory_leak();println!("Memory leaked successfully!");println!("\nViolating aliasing rules...");aliasing_violation();println!("Aliasing violation completed (somehow)");}#[cfg(test)]modtests{usesuper::*;#[test]fntest_use_after_free(){letval=use_after_free();// We're just calling it - the bug is inside
assert!(val==42||val!=42);// Always passes, but the UB is the problem
}#[test]fntest_aliasing_violation(){aliasing_violation();// Miri should catch this
}}
При запуске cargo test ошибок не будет -> тесты напишут Ок!.
В случае проверки с Miri, инструмент отловит проблемы Bug 1 и Bug 3. Утечки памяти не специализация Miri, может пропустить.
Bug 2 с утечкой памяти отловит Valgrind.
Когда что использовать?
Miri — когда ты пишешь:
unsafe код
Свои коллекции (Vec, HashMap)
FFI обёртки (здесь без unsafe не обойтись)
Хочешь поймать тонкие нарушения правил Rust
Valgrind — когда нужно:
Найти утечки памяти (Rust их почти не допускает, но C да)
Проверить программу на другом языке (C, C++, Fortran)
Отловить ошибки в уже готовом бинарнике, когда нет исходников
Proptest - это инструмент для тестирования на основе свойств (property-based testing). Он не проверяет память и не следит за выполнением кода. Вместо этого он автоматически генерирует тысячи случайных входных данных для твоей функции и проверяет, выполняются ли заданные тобой правила.
Пример работы
useproptest::prelude::*;// Функция, которая должна работать для любых чисел
fndivide(a: i32,b: i32)-> i32{a/b// Ой! А если b = 0? Будет паника!
}// Пишем свойство: "при любых a и b (где b != 0) деление работает"
proptest!{#[test]fntest_division_doesnt_panic(a: i32,bin0..1000){letresult=divide(a,b);prop_assert!(result.is_finite());}}
Для нахождения каких проблем нужен Proptest?
Тип проблемы
Пример
Крайние случаи
Деление на ноль, выход за границы массива
Неочевидные баги
Функция работает для 1, 2, 3, но ломается на 127 из-за переполнения
Нарушение инвариантов
“После сортировки длина массива не изменилась”
Алгоритмические ошибки
“Если я зашифрую и расшифрую — получится исходное сообщение”
Замыкания - анонимные функции. Их можно присвоить переменным и вызывать. Это также функция, которая ссылается на свободные переменные в своей области видимости. Базовое использование:
letadd_one=|x: i32|-> i32{x+1};println!("Add one to 5 = {}",add_one(5));// Add one to 5 = 6
letadd_two=|x|x+2;println!("Add two to 5 = {}",add_two(5));// Add two to 5 = 7
letadd=|a,b|a+b;println!("Sum of 5 and 6 = {}",add(5,6));// Sum of 5 and 6 = 11
letjust_number=||42;println!("Answer to all: {}",just_number());// Answer to all: 42
В отличие от функций, замыкания могут использовать переменные вне своего блока:
(0..3).for_each(|x|{println!("map i = {}",x*2);});letfactor=2;letmultiplier=|x|x*factor;println!("{}",multiplier(5));// 10
println!("Factor: {factor}");// factor ещё доступен тут
Это нужно для того, чтобы замыкание получило владение данным и пережило scope, в котором оно было объявлено.
Работа с итераторами
.map(<closure>) передаёт владение элементами итератора замыканию, чтобы их можно было трансформировать в другие элементы, которые далее возвращает замыкание.
.filter(<closure>) возвращает оригинальные элементы, когда предикат замыкания возвращает true. Таким образом, отдавать владение элементами замыканию нельзя, и нужно передавать по ссылке.
Можно вернуть элементы, когда предикат значения true, и сразу же их трансформировать. На вход он принимает замыкание, возвращающее Option<T>:
Если на выходе Some(value), значение включается в результат;
Если замыкание возвращает None, элемент исключается фильтром.
letnumbers=vec!["1","2","abc","4"];// Раздельно: filter() и потом map()
letresult: Vec<i32>=numbers.iter().filter(|s|s.parse::<i32>().is_ok())// фильтровать цифры
.map(|s|s.parse::<i32>().unwrap())// Перевести их в int
.collect();// Result: [1, 2, 4]
// Вместе: filter_map()
letresult: Vec<i32>=numbers.iter().filter_map(|s|s.parse::<i32>().ok())// фильтр и перевод в 1 шаг
.collect();// Result: [1, 2, 4]
Вложенные замыкания map()
leta=(0..=3).map(|x|x*2).map(|y|y-1);// первая итерация map(): 2, 4, 6
// вторая итерация map(): 1, 3, 5
foriina{println!("{i}");}
All
Замыкание all возвращает True, если все элементы в замыкании соответствуют условию.
leta: Vec<i32>=vec![1,2,3,4];print!("{}\n",a.into_iter().all(|x|x>1));// false
Для пустого вектора замыкание all вернёт True:
leta: Vec<i32>=vec![];print!("{}\n",a.into_iter().all(|x|x>1));// true
Цикл через замыкание vs for
usestd::collections::HashMap;pubfnmain(){letnum_vec=vec![1,2,1,3,5,2,1,4,6];letmutnumber_count: HashMap<i32,i32>=HashMap::new();forkeyinnum_vec{*number_count.entry(key).or_default()+=1;}/* for (k, v) in number_count {
print!("{} -> {}; ", k, v);
} */number_count.iter().for_each(|(k,v)|{print!("{} -> {}; ",k,v);});//цикл через замыкание итератора
}
letnumbers=vec![1,2,3,4,5];letproduct=numbers.iter().fold(1,|acc,&x|acc*x);println!("Product: {}",product);// 120
// код выше можно заменить на product()
От fold() отличается тем, что прерывает выполнение и возвращает Result(Err):
letstrings=["1","2","3","4","5"];// перевести строки в числа и суммировать их
letsum: Result<i32,_>=strings.iter().try_fold(0,|acc,&s|matchs.parse::<i32>(){Ok(num)=>Ok(acc+num),Err(e)=>Err(e),});matchsum{Ok(total)=>println!("Total: {}",total),// 15
Err(e)=>println!("Parse error: {}",e),}
Это изменяемая структура словарь (“dictionary” в Python), которая хранит пары “ключ->значение”. В Rust Prelude она не входит, макроса создания не имеет. Поэтому нужно указывать библиотеку явно и явно создавать структуру.
scores.insert(String::from("Gamma"),3);// вставка дважды значений по одному
scores.insert(String::from("Gamma"),6);// ключу сохранит последнее значение
Записывать значение, если у ключа его нет:
scores.entry(String::from("Delta")).or_insert(4);// entry проверяет наличие
// значения, or_insert возвращает mut ссылку на него, либо записывает новое
// значение и возвращает mut ссылку на это значение.
Записывать значение, если ключа нет. Если же у ключа есть значение, модифицировать его:
usestd::collections::HashMap;letmutmap: HashMap<&str,u32>=HashMap::new();map.entry("poneyland")// первое добавление
.and_modify(|e|{*e+=1}).or_insert(42);// добавит ключ "poneyland: 42"
assert_eq!(map["poneyland"],42);map.entry("poneyland")// второе добавление найдёт ключ со значением
.and_modify(|e|{*e+=1})// и модифицирует его
.or_insert(42);assert_eq!(map["poneyland"],43);
Записывать значение, если ключа нет, в виде результата функции. Эта функция получает ссылку на значение ключа key, который передаётся в .entry(key):
Упорядоченная по ключам K структура данных на основе B-дерева.
Ключевые отличия от HashMap:
Свойство
HashMap
BTreeMap
Внутренняя структура
Хэш таблица
Дерево поиска
Упорядоченность
Не гарантированная
Ключи всегда упорядочены
Скорость
O(1)
O(log n)
Требования
Hash + Eq
Ord
Потребление памяти
Выше
Ниже
Применение
Когда нужно сразу сортировать данные:
letmutscores=BTreeMap::new();scores.insert("Charlie",85);scores.insert("Alice",92);scores.insert("Bob",78);// Итерация сразу в отсортированном порядке по ключам
for(name,score)in&scores{println!("{}: {}",name,score);// Alice, Bob, Charlie
}// Получить 1ый и последний элементы
println!("{:?}",scores.first_key_value());// ("Alice", 92)
println!("{:?}",scores.last_key_value());// ("Charlie", 85)
Работа с диапазонами значений:
// Диапазоны заданы кортежами (нижняя_граница, верхняя_граница)
letmutprice_ranges=BTreeMap::new();price_ranges.insert((0,10),"Budget");price_ranges.insert((11,50),"Standard");price_ranges.insert((51,100),"Premium");price_ranges.insert((101,1000),"Luxury");letquery_price=42;// Поиск по диапазонам (линейный в данном случае)
for((low,high),category)in&price_ranges{ifquery_price>=*low&&query_price<=*high{println!("Price ${} is in category: {} (range: {}-{})",query_price,category,low,high);break;}}
useserde_jsonletmutconfig=BTreeMap::new();config.insert("zebra","animal");config.insert("apple","fruit");config.insert("banana","fruit");// сериализация в JSON с порядком элементов
letjson=serde_json::to_string_pretty(&config).unwrap();println!("{}",json);// ключи будут в порядке: apple, banana, zebra
Для небольших коллекций (< 1000 элементов) или когда требуется отсортированный порядок, BTreeMap часто предпочтительнее. Для больших коллекций, где нужна максимальная скорость, а порядок не имеет значения, HashMap обычно лучше.
Оба типа представляют множества для хранения уникальных элементов.
Отличия HashSet и BTreeSet
Множество
HashSet
BTreeSet
Сортировка
Случайный порядок
Да
Сложность алгоритма
O(1) в среднем
O(log n)
Потребление памяти
Выше (hash-таблица)
Ниже
Запросы диапазонов значений
Нет
Да
Типажи
T: Hash + Eq
T: Ord
Работа с HashSet
usestd::collections::HashSet;fnmain(){// Создание
letmutcolors=HashSet::new();// Добавление элеметов
colors.insert("red");colors.insert("green");colors.insert("blue");colors.insert("red");// дубликат - не будет добавлен!
println!("HashSet: {:?}",colors);// порядок произвольный
// Проверка существования элемента
ifcolors.contains("green"){println!("Contains green!");}// Итерация (порядок не гарантирован)
forcolorin&colors{println!("Color: {}",color);}// Удаление элемента
colors.remove("blue");// Объединение двух HashSet
letmutwarm_colors=HashSet::new();warm_colors.insert("red");warm_colors.insert("yellow");warm_colors.insert("orange");letall_colors: HashSet<_>=colors.union(&warm_colors).collect();println!("All colors: {:?}",all_colors);}
Работа с BTreeSet
usestd::collections::BTreeSet;fnmain(){// Создание BTreeSet
letmutnumbers=BTreeSet::new();// Вставка элементов (авто-сортировка!)
numbers.insert(5);numbers.insert(2);numbers.insert(8);numbers.insert(1);numbers.insert(5);// дубликат - не будет добавлен!
println!("BTreeSet: {:?}",numbers);// сортировка всегда: {1, 2, 5, 8}
// Проверка существования элемента
ifnumbers.contains(&2){println!("Contains 2!");}// Итерация по порядку
fornumin&numbers{println!("Number: {}",num);// 1, 2, 5, 8
}// Получить первый и последний элементы
ifletSome(first)=numbers.first(){println!("First element: {}",first);// 1
}ifletSome(last)=numbers.last(){println!("Last element: {}",last);// 8
}// Запрос диапазона значений
letrange: Vec<_>=numbers.range(2..=5).collect();println!("Numbers between 2 and 5: {:?}",range);// [2, 5]
// Удаление элемента
numbers.remove(&5);}
HashSet -> Vector
Простой способ:
usestd::collections::HashSet;letset: HashSet<char>=['a','b','c','d'].into_iter().collect();// Перевод в Vec<char> - расстановка элементов произвольная
letvec: Vec<char>=set.into_iter().collect();println!("Vec: {:?}",vec);// Example: ['c', 'a', 'd', 'b']
Вектор - множество данных одного типа, количество которых можно изменять: добавлять и удалять элементы. Нужен, когда:
требуется собрать набор элементов для обработки в других местах;
нужно выставить элементы в определённом порядке, с добавлением новых элементов в конец;
нужно реализовать стэк;
нужен массив изменяемой величины и расположенный в куче.
Методы
// Задание пустого вектора:
// let mut a test_vector: Vec<i32> = Vec::new();
// Задание вектора со значениями через макрос:
letmuttest_vector=vec![1,2,3,4];test_vector.push(42);// добавить число 42 в конец mut вектора
letSome(last)=test_vector.pop();// удаляет и возвращает последний элемент (возвращает Option<T>)
test_vector.remove(0);// удалить первый элемент =1
foriin&muttest_vector{// пройти вектор как итератор для вывода
*i+=1;// изменять значения при их получении требует делать '*' dereference
println!("{i}");}println!("Vector length: {}",test_vector.len());// количество элементов
Элемент можно получить либо с помощью индекса, либо с помощью безопасного метода get:
letmuttest_vector=vec![1,2,3,4,5];println!("Third element of vector is: {}",&test_vector[2]);// индекс
letthird: Option<&i32>=test_vector.get(2);// безопасный метод get
matchthird{Some(third)=>println!("Third element of vector is: {}",third),None=>println!("There is no third element")}
Разница в способах в реакции на попытку взять несуществующий элемент за пределами вектора. Взятие через индекс приведёт к панике и остановке программы. Взятие с помощью get сопровождается проверкой и обработкой ошибки.
Удаление элемента
Метод .remove(index):
letmutnumbers=vec![1,2,3,4];numbers.remove(1);// удаляет элемент с индексом 1
println!("{:?}",numbers);// [1, 3, 4]
.remove() сдвигает все последующие элементы, что может быть дорого для больших векторов (O(n));
Более быстрый вариант swap_remove(index) - меняет местами целевой элемент для удаления и последний элемент, потом сокращает размер вектора на 1. Это намного дешевле .remove(), но немного перемешивает вектор;
Возвращает удалённый элемент;
Требует mut, так как изменяет вектор;
Индекс должен быть в пределах длины, иначе паника.
Хранение элементов разных типов в векторе
Rust нужно заранее знать при компиляции, сколько нужно выделять памяти под каждый элемент. Если известны заранее все типы для хранения, то можно использовать промежуточный enum:
Смена элементов при сравнении, метод .sort_by() принимает замыкание (closure) для пользовательской сортировки:
number_vector.sort_by(|a,b|b.cmp(a));
|a, b| — это замыкание;
b.cmp(a) возвращает порядок: Ordering::Less, Equal или Greater. Инверсия (b.cmp(a) вместо a.cmp(b)) даёт убывающий порядок.
Альтернатива: .sort_by_key() для сортировки по вычисляемому ключу:
letmutnumbers=vec![3,1,4,1,5];numbers.sort_by_key(|&x|-x);// по убыванию через отрицание
println!("{:?}",numbers);// [5, 4, 3, 1, 1]
Если вернуть Reverse со ссылкой и без *, это приведёт к проблеме с временем жизни.
Сортировка вектора по ключу
usestd::collections::HashSet;fnmain(){letmutvowels=HashSet::new();vowels.insert('e');vowels.insert('a');vowels.insert('i');vowels.insert('o');vowels.insert('u');// Конвертация в Vec и сортировка
letmutvowel_vec: Vec<char>=vowels.into_iter().collect();// Свой порядок сортировки: a, e, i, o, u
letvowel_order=|c: &char|matchc{'a'=>0,'e'=>1,'i'=>2,'o'=>3,'u'=>4,_=>5,};vowel_vec.sort_by_key(vowel_order);println!("Sorted vowels: {:?}",vowel_vec);// ['a', 'e', 'i', 'o', 'u']
}
Дедупликация вектора
Удаление одинаковых элементов в векторе, похоже на работу с HashSet.
lets="aabbccdddeeeeffffeee";letmutchars: Vec<char>=s.chars().collect();// Сначала отсортировать, чтобы собрать одинаковые элементы вместе
chars.sort_unstable();// dedup() удаляет на месте одинаковые СТОЯЩИЕ РЯДОМ в векторе элементы
chars.dedup();// собрать назад в String:
letunique_s: String=chars.into_iter().collect();
Сделать новый проект, добавить в него библиотеку cargo add current_platform. Далее создаём и запускаем код проверки среды компиляции и исполнения:
usecurrent_platform::{COMPILED_ON,CURRENT_PLATFORM};fnmain(){println!("Run from {}! Compiled on {}.",CURRENT_PLATFORM,COMPILED_ON);}
Посмотреть текущую ОС компиляции: rustc -vV
Посмотреть список ОС для кросс-компиляции: rustc --print target-list
Формат списка имеет поля <arch><sub>-<vendor>-<sys>-<env>, например, x86_64-apple-darwin => macOS на чипе Intel.
Настройка кросс-компилятора
Нужно установить cross: cargo install cross установит его по пути $HOME/.cargo/bin
Запуск кода на компиляцию под ОС Windows: cross run --target x86_64-pc-windows-gnu => в папке target/x86_64-pc-windows-gnu/debug получаем EXE-файл с результатом.
❗Компиляция проходит через WINE.
Проверка среды компиляции
Cross поддерживает тестирование других платформ. Добавка проверки:
Запустить проверку локально: cargo test
Запустить проверку с кросс-компиляцией: cross test --target x86_64-pc-windows-gnu
На Linux/macOS проверка пройдёт, а вот при компиляции под Windows - нет:
`test tests::test_compiled_on_equals_current_platform … FAILED
Добавка платформенно-специфичного кода
Можно вписать код, который запустится только на определённой ОС, например, только на Windows:
usecurrent_platform::{COMPILED_ON,CURRENT_PLATFORM};#[cfg(target_os="windows")]fnwindows_only(){println!("This will only print on Windows!");}fnmain(){println!("Run from {}! Compiled on {}.",CURRENT_PLATFORM,COMPILED_ON);#[cfg(target_os="windows")]{windows_only();}}
Перечисление — это тип данных, который позволяет определить набор именованных значений (вариантов). Каждый вариант может быть просто именем или содержать дополнительные данные.
enumMoney{Rub,Kop}
Здесь мы определили перечисление Money с двумя вариантами: Rub, и Kop. Эти варианты не содержат дополнительных данных — они просто имена, которые представляют возможные состояния. В терминах Rust такие варианты без данных часто называют “unit-like” (похожими на Unit), но это не совсем то же самое, что массив или указатели.
Unit
“Unit” в Rust — это специальный тип (), который имеет только одно значение, тоже обозначаемое как (). Это что-то вроде “пустого значения”, которое часто используется, когда функция ничего не возвращает. Например:
fn do_nothing() {
// Ничего не возвращаем, implicitly возвращается ()
}
В случае с Money каждый вариант (Rub и Kop) сам по себе не является типом (), но его можно рассматривать как “unit-like”, потому что он не несёт дополнительных данных. Это просто маркер, который говорит: “Я одно из двух состояний”.
Enum в памяти
Внутри памяти Money представлен как небольшое целое число (обычно 1 байт для простых перечислений вроде этого), называемое “дискриминантом”. Этот дискриминант указывает, какой вариант сейчас используется:
Money::Rub → 0
Money::Kop → 1
Но это внутренняя реализация. Для программиста это просто разные состояния.
match
Аналог switch в других языках, однако, круче: его проверка не сводится к bool, а также реакция на каждое действие может быть блоком:
n - привязка (binding). Когда ты пишешь n if n > 0, то говоришь: “возьми значение number и назови его n для этой ветки. Затем проверь условие if n > 0. Если оно истинно, выполни действие”. Обычно match используется с точными значениями (например, 1 => ..., 2 => ...), но добавление if позволяет проверять более сложные условия, как в этом примере (положительное, отрицательное или ноль). Это называется guards (охрана) в Rust.
Ещё пример:
fnmain(){letm=Money::Kop;println!("Я нашёл кошелёк, а там {}p",match_value_in_kop(m));}fnmatch_value_in_kop(money: Money)-> u8{matchmoney{Money::Rub=>100,Money::Kop=>{println!("Счастливая копейка!");1}}}
match как выражение
fnmain(){letnumber=3;letresult=matchnumber{1=>"один",2=>"два",_=>"другое",};println!("Результат: {}",result);// Вывод: Результат: другое
}
Проверка условия и запуск соответствующего метода:
structState{color: (u8,u8,u8),position: Point,quit: bool,}implState{fnchange_color(&mutself,color: (u8,u8,u8)){self.color=color;}fnquit(&mutself){self.quit=true;}fnecho(&self,s: String){println!("{}",s);}fnmove_position(&mutself,p: Point){self.position=p;}fnprocess(&mutself,message: Message){matchmessage{// проверка и запуск одного из методов
Message::Quit=>self.quit(),Message::Echo(x)=>self.echo(x),Message::ChangeColor(x,y,z)=>self.change_color((x,y,z)),Message::Move(x)=>self.move_position(x),}}}
Использование Option как enum
fndivide(a: i32,b: i32)-> Option{ifb==0{None}else{Some(a/b)}}fnmain(){matchdivide(10,2){Some(result)=>println!("Result: {}",result),// Result: 5
None=>println!("Division by zero!"),}}
if let
В случае, когда выбор сводится к тому, что мы сравниваем 1 вариант с заданным паттерном и далее запускаем код при успехе, а в случае неравенства ничего не делаем, можно вместо match применять более короткую конструкцию if-let:
letconfig_max=Some(3u8);matchconfig_max{Some(max)=>println!("The maximum is configured to be {}",max),_=>(),// другие варианты ничего не возвращают
}
Превращается в:
letconfig_max=Some(3u8);ifletSome(max)=config_max{println!("The maximum is configured to be {}",max);}
Применение if-let - это синтаксический сахар, укорачивает код, однако, лишает нас проверки наличия обработчиков на все варианты возвращаемых значений как в конструкции match.
Сравнение величин
Для сравнения значений в переменных есть метод std::cmp, который возвращает объект типа enum Ordering с вариантами:
usestd::cmp::Ordering;usestd:io;fnmain(){letsecret_number=42;letmutguess=String::new();io::stdin().read_line(&guess).expect("Read line failed!");letguess:i32=guess.trim().parse().expect("Error! Non-number value entered.");matchguess.cmp(&secret_number){Ordering::Greater=>println!("Number too big"),Ordering::Less=>println!("Number too small"),Ordering::Equal=>println("Found exact number!")}}
Option — это перечисление (enum), которое используется, когда значение может быть либо “чем-то” (Some), либо “ничем” (None). Это замена привычным null или nil из других языков, но с важным отличием: в Rust вы обязаны явно обработать возможность отсутствия значения. Определение Option в стандартной библиотеке:
enumOption<T>{Some(T),None,}
где:
T — это любой тип данных (например, i32, String и т.д.).
Some(T) — значение есть, и оно равно T.
None — значения нет.
Result
Result — это перечисление, которое используется для операций, которые могут завершиться успехом (Ok) или неудачей (Err):
enumResult<T,E>{Ok(T),// Успех с результатом типа T
Err(E),// Ошибка с типом E
}
где:
T — тип возвращаемого значения при успехе.
E — тип ошибки при неудаче.
Обработка Option и Result
Использовать match и обработать все варианты поведения;
unwrap — “дай мне значение или паника” (если None или Err, программа крашится);
unwrap_or — “дай мне значение или что-то другое” (если None или Err, возвращает запасное значение, которое ты указал);
expect — “дай мне значение или паника с моим текстом” (как unwrap, но с твоим сообщением при краше);
is_some — “скажи, есть ли там значение?” (возвращает true, если Some в Option, и false, если None);
is_none — “скажи, пусто ли там?” (возвращает true, если None в Option, и false, если Some).
Если коротко: unwrap, unwrap_or и expect пытаются достать значение и что-то с ним сделать, а is_some и is_none просто проверяют, что внутри, не трогая само значение.
Обработка ошибки с map_err()
.map_err() — это метод, который позволяет преобразовать тип ошибки, не трогая успешное значение.
result.map_err(|err|{// преобразуем старую ошибку err в новую
new_error})
Работа map_err() с цепочками операций:
usestd::fs::File;usestd::io::Read;usestd::num::ParseIntError;// Создаём свой тип ошибки для понятного описания
#[derive(Debug)]enumMyError{IoError(String),ParseError(String),}fnread_and_parse()-> Result<i32,MyError>{// Пробуем открыть файл
letmutfile=File::open("number.txt").map_err(|e|MyError::IoError(format!("Ошибка открытия: {}",e)))?;// Пробуем прочитать содержимое
letmutcontents=String::new();file.read_to_string(&mutcontents).map_err(|e|MyError::IoError(format!("Ошибка чтения: {}",e)))?;// Пробуем распарсить число
letnumber: i32=contents.trim().parse().map_err(|e|MyError::ParseError(format!("Ошибка парсинга: {}",e)))?;Ok(number)}fnmain(){matchread_and_parse(){Ok(num)=>println!("Число: {}",num),Err(MyError::IoError(msg))=>println!("IO Ошибка: {}",msg),Err(MyError::ParseError(msg))=>println!("Ошибка парсинга: {}",msg),}}
В широком использовании удобнее использовать context из библиотеки anyhow. Однако, map_err нужен для преобразования в другой тип ошибки:
enumMyError{IoError(std::io::Error),ParseError(String),}fnparse_config()-> Result<(),MyError>{letcontent=std::fs::read_to_string("config.txt").map_err(MyError::IoError)?;// Преобразуем в наш тип
// ... обработка
Ok(())}
Ошибки, не реализующие std::error::Error:
// Некоторый API возвращает Result<..., ()>
fnold_api()-> Result<i32,()>{Ok(42)}// context() не работает, потому что () не реализует Error
letvalue=old_api().map_err(|_|anyhow::anyhow!("старое API вернуло ошибку"))?;
В коде, использующем anyhow, лучше context() и with_context() перед map_err(|e| anyhow!(...)). А map_err() для случаев, когда нужно преобразовать ошибку в другой тип или реализовать нестандартную логику обработки.
Оператор ‘?’
Оператор ? используется в функциях, возвращающих Result. Он автоматически возвращает Err из функции, если результат — Err, или извлекает значение из Ok:
fndivide(a: i32,b: i32)-> Result<i32,String>{ifb==0{Err(String::from("Деление на ноль!"))}else{Ok(a/b)}}fnsafe_division(a: i32,b: i32)-> Result<i32,String>{letresult=divide(a,b)?;Ok(result*2)// Удваиваем результат
}fnmain(){println!("{:?}",safe_division(10,0));// Err("Деление на ноль!")
println!("{:?}",safe_division(10,2));// Ok(10)
}
Ошибки без восстановления
Ряд ошибок приводит к вылету приложения. Также можно вручную вызвать вылет командой panic!:
fnmain(){panic!("Battery critically low! Shutting down to prevent data loss.");}
При этом некоторое время тратится на закрытие приложения, очистку стека и данных. Можно переложить это на ОС, введя настройку в Cargo.toml:
[profile.release]panic='abort'
Пользовательские ошибки с enum
Иногда стандартных типов ошибок (например, String) недостаточно. Вы можете создать свои собственные ошибки с помощью enum:
enumMathError{// введём свой enum с типами ошибок
DivisionByZero,NegativeNumber,}fndivide_with_custom_error(a: i32,b: i32)-> Result<i32,MathError>{ifb==0{Err(MathError::DivisionByZero)}elseifa<0||b<0{Err(MathError::NegativeNumber)}else{Ok(a/b)}}fnmain(){matchdivide_with_custom_error(10,0){Ok(value)=>println!("Результат: {}",value),Err(MathError::DivisionByZero)=>println!("Ошибка: деление на ноль"),Err(MathError::NegativeNumber)=>println!("Ошибка: отрицательное число"),}}
Преимущества:
Чёткое определение всех возможных ошибок.
Легко расширять (добавьте новый вариант в enum).
Стратегии работы с ошибками
Подготовка примера
Допустим, мы берём вектор из строк-чисел, складываем их и возвращаем сумму как строку:
fnsum_str_vec(strs: Vec<String>)-> String{letmutaccum=0i32;forsinstrs{accum+=to_int(&s);// to_int = заготовка, см. ниже реализацию
}returnaccum.to_string();}fnmain(){letv=vec![String::from("3"),String::from("4")];// Правильный ввод
lettotal=sum_str_vec(v);println!("Total equals: {:?}",total);letv=vec![String::from("3"),String::from("abc")];// Неправильный ввод
lettotal=sum_str_vec(v);println!("Total equals: {:?}",total);}
Для конвертации строки в числа, нужно реализовать функцию to_int в соответствии со стратегиями обработки ошибочного ввода. Конвертацию мы делаем функцией parse(), которая возвращает тип Result<T,E>, где T - значение, E - код ошибки.
Стратегия 1 - паника
В случае неверного ввода, программа полностью останавливается в панике. Метод unwrap() у типа Result<T,E> убирает проверки на ошибки и есть договор с компилятором о том, что ошибки в этом месте быть не может. Если она есть, программа падает с паникой:
fnto_int(s: &str)-> i32{s.parse().unwrap()}
Стратегия 2 - паника с указанием причины
В случае неверного ввода, программа сообщает фразу, заданную автором, далее полностью останавливается в панике. Метод expect() аналогичен unwrap(), но выводит сообщение:
fnto_int(s: &str)-> i32{s.parse().expect("Error converting from string")}
Стратегия 3 - обработать то, что возможно обработать
Можно сконвертировать и прибавить к результату те строки, которые позволяют это сделать, проигнорировать остальные. Метод unwrap_or() позволяет указать возвращаемое значение в случае ошибки:
Более предпочтительный вариант использовать закрытие unwrap_or_else(), так как метод unwrap_or() будет вызван ДО того как будет отработана основная команда, ВНЕ ЗАВИСИМОСТИ от того, будет ли её результат Some или None. Это потеря производительности, а также потенциальные глюки при использовании внутри unwrap_or() сложных выражений. Закрытие unwrap_or_else() будет вызвано только в случае None, иначе же эта ветка не обрабатывается:
Стратегия 5 - в случае проблем, передать всё в основную программу
Вместо передачи значения из функции, в случае каких-либо проблем, мы возвращаем None:
fnsum_str_vec(strs: Vec<String>)-> Option<String>{letmutaccum=0i32;forsinstrs{accum+=to_int(&s)?;// в случае None, ? передаёт его далее на выход
}Some(accum.to_string())// на выход пойдёт значение или None
}
Стратегия 6 - передать всё в основную программу с объяснением ошибки
Мы возвращаем проблему в основную программу с объясением проблемы. Для этого заводим структуру под ошибку, и передаём уже не объект Option<T>, а объект Result<T,E>, где E = SummationError. Для такого объекта есть метод ok_or(), который либо передаёт значение, либо передаёт ошибку нужного типа:
Вместо выдумывать свой собственный тип и конвертировать вывод метода parse() из Result<T,E> в Option<T>, а потом обратно, можно сразу протащить ошибку в объекте Result<T,E> в главную программу:
usestd::num::ParseIntError;// тип ошибки берём из библиотеки
fnto_int(s: &str)-> Result<i32,ParseIntError>{s.parse()// parse возвращает просто Result<T,E>
}fnsum_str_vec(strs: Vec<String>)-> Result<String,ParseIntError>{letmutaccum=0i32;forsinstrs{accum+=to_int(&s)?;}// ? передаёт ошибку нужного типа далее
Ok(accum.to_string())}
Однако, мы хотим скрыть подробности работы и ошибки от главной программы и передать ей ошибку в понятном виде, без разъяснения деталей её возникновения. Для этого можно сделать трансляцию ошибки из библиотечной в собственный тип, и далее передать методом map_err():
Оператор ? можно использовать только в функциях для возврата совместимых значений типа Result<T,E>, Option<T> или иных данных со свойством FromResidual. Для работы такого возврата в заголовке функции должен быть прописан возврат нужного типа данных. При использовании ? на выражении типа Result<T,E> или Option<T>, ошибка Err(e) или None будет возвращена рано из функции, а в случае успеха - выражение вернёт результат, и функция продолжит работу.
Пример функции, которая возвращает последний символ 1ой строки текста:
fnlast_char_of_first_line(text: &str)-> Option<char>{text.lines().next()?.chars().last()}// lines() возвращает итератор на текст
// next() берёт первую строку текста. Если текст пустой - сразу возвращаем None
Ввод-вывод построен вокруг модуля стандартной библиотеки std::io, который предоставляет инструменты для работы с потоками данных, а также модуля std::fs, предназначенного для операций с файловой системой.
Чтение файлов
Чтение текста из файлов в строку с Read trait
Для чтения файлов, нужно сначала добавить несколько методов из библиотек: FIle - открытие файлов и Read - чтение.
usestd::fs::File;// импорт File
usestd::io::Read;// импорт Read
fnmain()-> std::io::Result<()>{// отлов ошибок ввода/вывода
letfilename="test.txt".to_string();// путь до файла в корне проекта
letmutfiletext=String::new();letmutfilehandle=File::open(filename)?;filehandle.read_to_string(&mutfiletext)?;// чтение в строку
println!("{filetext}");Ok(())}
Простое чтение текста из файлов в строку
Вариант выше подходит, когда нужен контроль над процессом, частичное чтение файла. Для задачи просто прочитать и закрыть:
Чтение файла в память целиком как вектора байтов - для бинарных файлов, либо для частого обращения к содержимому:
usestd::io::Read;usestd::{env,fs,io,str};fnmain()-> io::Result<()>{letmutfile=fs::File::open("test_file.txt")?;letmutcontents=Vec::new();file.read_to_end(&mutcontents);println!("File contents: {:?}",contents);// вывод байт
lettext=matchstr::from_utf8(&contents){// перевод в строку UTF8
Ok(v)=>v,Err(e)=>panic!("Invalid UTF-8: {e}"),};println!("Result: {text}");// вывод строкой
Ok(())}
Запись в файлы
Быстрое создание файла + запись в файл:
lettest_text="Some text".to_string();std::fs::write("out.txt",test_text).unwrap();// быстрая запись в файл
Такая запись предполагает, что контент файла уже готов в памяти приложения.
Запись с подготовкой:
usestd::fs::File;usestd::io::Write;fnmain()-> io::Result<()>{// создать новый файл или обнулить имеющийся:
letmutfile=File::create("report.log")?;file.write_all(b"report.log");// запись байтов в файл
Ok(())}
В этом варианте файл не нужно весь держать в памяти: файл на диске можно оставить открытым для дописывания позже в приложении.
Буферизация
Чтение текста через буфер
Нужно добавить к библиотеке File также библиотеку организации буфера чтения, а также обработать ошибки открытия файла и чтения.
usestd::fs::File;usestd::io::{BufReader,Read};fnmain()-> std::io::Result<()>{letfile=File::open("sportinv.csv")?;// обернуть File в буферизированный читатель (блоки по 8kb by default):
letmutreader=BufReader::new(file);letmuttext=String::new();reader.read_to_string(&muttext)?;println!("{text}");Ok(())}
Чтение текста из больших файлов в буфер по строчкам
usestd::fs::File;usestd::io::{BufWriter,Write};fnmain()-> std::io::Result<()>{letfile=File::create("output.txt")?;letmutwriter=BufWriter::new(file);writer.write_all(b"Test output!")?;writer.flush()?;// Сброс буфера в файл
Ok(())}
Запись и дополнение файла через буфер по строчкам
usestd::fs::File;usestd::io::{BufWriter,Write};fnmain()-> std::io::Result<()>{letfile=File::create("output.txt")?;letmutwriter=BufWriter::new(file);writeln!(writer,"Первая строка")?;// макрос записи в поток
writeln!(writer,"Вторая строка")?;writer.flush()?;Ok(())}
File::create всегда обнуляет файл, если он уже есть. Чтобы дописать файл, нужно использовать OpenOptions и указать режим append:
usestd::fs::OpenOptions;// OpenOptions вместо File
usestd::io::{BufWriter,Write};fnmain()-> std::io::Result<()>{letfile=OpenOptions::new().append(true)// +режим дозаписи
.create(true)// создать, если файла нет
.open("output.txt")?;// открыть файл
//let file = File::create("output.txt")?;
letmutwriter=BufWriter::new(file);writeln!(writer,"Первая строка")?;writeln!(writer,"Вторая строка")?;writer.flush()?;Ok(())}
Копирование файлов
Функция std::fs::copy принимает исходный и целевой пути и возвращает Result<u64, std::io::Error>, где u64 — количество скопированных байт.
Если целевой файл уже существует, он будет перезаписан.
Перемещение файлов
Функция std::fs::rename принимает исходный и целевой пути и возвращает Result<(), std::io::Error> (при успехе ничего не возвращает (()), при ошибке — описание проблемы):
Если целевой файл существует, он будет перезаписан (на той же файловой системе);
Перемещение между разными файловыми системами может не сработать, надо сначала скопировать, а затем удалить исходный файл вручную.
Удаление файлов
Функция std::fs::remove_file принимает путь к файлу и возвращает результат типа Result<(), std::io::Error>, что позволяет обработать возможные ошибки (например, если файла не существует):
Пути в Rust обрабатываются через структуры Path и PathBuf, где Path — это неизменяемый срез пути, аналогичный str:
usestd::path::Path;fnmain(){letpath=Path::new("/home/alex/example.txt");// ссылка на путь
println!("Extension: {:?}",path.extension());// Some("txt")
println!("File name: {:?}",path.file_name());// Some("example.txt")
println!("File exists? {}",path.exists());// false
}
Методы вроде extension() и file_name() возвращают Option, т.к. путь может не содержать этих элементов.
PathBuf — это изменяемая версия пути, аналогичная String:
usestd::path::PathBuf;fnmain(){letmutpath=PathBuf::from("/home/alex/");// push добавляет компонент к пути с учетом разделителей ОС:
path.push("test.txt");println!("Path: {:?}",path);// /home/alex/test.txt
}
Используйте Path для проверки существующих путей, а PathBuf — для построения новых.
Чтение файла по имени из строки или PathBuf
Объект PathBuf реализует AsRef trait, это даёт возможность универсально передавать его:
usestd::fs;usestd::path::Path;// Функция забирает как строку, так и Path объект
fnread_file<P: AsRef<Path>>(path: P)-> String{// .as_ref() переводит полученное в &Path
fs::read_to_string(path.as_ref()).unwrap()}fnmain(){// оба работают:
letcontent1=read_file("hello.txt");// &str
letcontent2=read_file(Path::new("world.txt"));// &Path
}
В Rust есть управление потоком программы через конструкции IF, ELSE IF, ELSE:
lettest_number=6;iftest_number%4==0{println!("Divisible by 4");}elseiftest_number%3==0{// Проверка останавливается на первом
println!("Divisible by 3");// выполнимом условии, дальнейшие проверки
}elseiftest_number%2==0{// пропускаются.
println!("Divisible by 2");}else{println!("Number is not divisible by 4, 3 or 2");}
Конструкция IF является выражением (expression) и возвращает значение:
letcondition=true;letnumber=ifcondition{"aa"}else{"ab"};// присваивание результата IF
println!("Number is {number}");
Используйте if как выражение для компактности. Для сложных случаев лучше переходить к match.
IF LET
В отличие от match, в котором нужно обязательно перебрать все переданные варианты, if let позволяет обработать лишь один вариант, отбросив все остальные (не реагируя на них). В то время как match можно сравнить с вендинговым автоматом, if let - это фильтр.
Применение - проверить, что в Option есть значение:
letusername: Option<String>=Some("cool_teen".to_string());// длинный путь с match:
matchusername{Some(name)=>println!("Hello {}!",name),None=>{},// ненужный пустой блок 🤮
}// короткий путь:
ifletSome(name)=username{println!("Hello {}!",name);// работает только если Some существует
}// Не надо обрабатыватьNone!
Применение - проверить, что Result успешен:
letfile_result: Result<File,std::io::Error>=File::open("config.txt");// нас волнует только, если сработало:
ifletOk(file)=file_result{println!("File opened successfully!");// далее использовать 'file'
}
if let работает с любым паттерном:
// проверить точное значение:
iflet42=answer{println!("The meaning of life!");}// сравнить 1ый элемент кортежа
letcoordinates=(10,20);iflet(x,20)=coordinates{println!("Y is 20, X is {}",x);}// проверить несколько условий с помощью `|` (or)
enumStatus{Active,Pending,Inactive,}letstate=Status::Pending;ifletStatus::Active|Status::Pending=state{println!("User can log in");}
❗Эффективно применять if let тогда, когда условие “все остальные случаи” _ => {} в конструкции match пустое.
IF LET ELSE
Можно комбинировать if let и else для обработки “противоположного” результата:
ifletSome(score)=high_score{println!("New high score: {}!",score);}else{println!("No high score yet. Play a game!");}
LOOPS
Три варианта организовать цикл: через операторы loop, while, for.
Loop
loop - организация вечных циклов. Конструкция loop является выражением (expression), поэтому возвращает значение.
letmutcounter=0;letresult=loop{counter+=1;ifcounter==10{breakcounter*2;// выход из вечного цикла
}};// ";" нужно, т.к. было выражение
println!("The result is {result}");
Если делать вложенные циклы, то можно помечать их меткой, чтобы выходить с break на нужный уровень.
for - цикл по множествам элементов. В том числе можно задать подмножество чисел.
foriin(1..10).rev(){// .rev() - выдача подмножества в обратную сторону
println!("Value: {i}");}println!("ЗАПУСК!");
Функции
Вызов функции: указатель на начало функции кладётся на стек (под каждую функцию выделяется место на стеке - stack frame). Стек имеет ограничения по размеру. Можно это проверить, написав пример:
fnmain(){a();}fna(){println!("Calling B!");b();}fnb(){println!("Calling C!");c();}fnc(){println!("Calling A!");a();// бесконечный цикл вызовов
}
При запуске программы она бесконечно вызывает функции, пока не исчерпает место в stack frame функции main, и тогда программа падает с ошибкой:
thread 'main' has overflowed its stack
fatal runtime error: stack overflow
Abort trap: 6
Передача функций как аргументов
Тип функции — её сигнатура.
// Функция apply принимает 2 параметра:
// 1. x типа i32 (32-битное целое число)
// 2. f - функцию с сигнатурой fn(i32) -> i32,
// т.е. которая принимает i32 и возвращает i32
// Сама apply возвращает i32
fnapply(x: i32,f: fn(i32)-> i32)-> i32{// Применяем переданную функцию f к аргументу x
// и возвращаем результат
f(x)}// Функция принимает x типа i32 и возвращает x * 2 тоже типа i32
fndouble(x: i32)-> i32{x*2// удваивает входное число
}fnmain(){// Вызываем apply с двумя аргументами:
// 1. Число 5
// 2. Функция double
// double будет применена к 5, то есть 5 * 2 = 10
letresult=apply(5,double);println!("Удвоенное: {}",result);// Вывод: Удвоенное: 10
}
Exit
В Rust для “нормального” завершения программы используется функция std::process::exit из стандартной библиотеки. Она завершает программу немедленно с заданным кодом возврата, не вызывая панику.
usestd::process;fnmain(){println!("До выхода");process::exit(0);// Завершаем программу с кодом 0 (успех)
println!("Это не выведется");}
process::exit(code: i32) принимает код возврата (i32), который передаётся операционной системе.
Код 0 обычно означает “успешное завершение”, а ненулевые значения (напримр, 1) — “ошибка”.
После вызова exit программа завершается мгновенно — никакой код ниже не выполняется, даже если есть незавершённые операции.
Return
Можно использовать return в main. Это не то же самое, что exit (не мгновенно прерывает), но подходит для естественного завершения:
fnmain(){println!("Работаем...");return;// Завершаем с кодом 0
println!("Это не выведется");}
Result
Можно возвращать Result из main, чтобы указать успех или ошибку:
fnmain()-> Result<(),i32>{println!("Работаем...");Ok(());// Успех, код 0
// или Err(1) для ошибки с кодом 1
}
Если нужно мгновенное завершение с кодом возврата — используй std::process::exit;
Если надо завершить программу “правильно” в конце main — просто return или Result;
panic! - для случаев, когда программа должна “упасть” из-за ошибки.
Generics нужны для того, чтобы не повторять один и тот-же код несколько раз для разных типов данных. Это один из трёх основных способов экономии на повторении кода наравне с макросами и интерфейсами traits.
Пример: нужно сортировать 2 набора данных - массив чисел, массив символов.
Вместо того, чтобы писать 2 почти идентичные функции под 2 типа данных, можно объединить оба типа в 1 функцию, указав “неопределённый тип”.
Note
Нужно учесть, что не все типы данных имеют возможность сравнения объектов между собой, возможность выстроить их в порядок (Order). Поэтому в примере ниже надо дополнить тип в заголовке интерфейсом-свойством (trait) порядка.
fnlargest_universal<T: std::cmp::PartialOrd>(list: &[T])-> &T{// <T> = неопределённый тип, со свойством упорядочивания PartialOrd
letmutlargest=&list[0];foriteminlist{iflargest<item{largest=item;}}largest}fnmain(){letnum_list=vec![11,6,33,56,13];//упорядочить числа
println!("Largest number: {}",largest_universal(&num_list));letchar_list=vec!['y','m','a','q'];//упорядочить символы в той же функции
println!("Largest char: {}",largest_universal(&char_list));}
Структуры с неопределёнными типами
Можно создавать структуры, тип данных которых заранее неопределён. Причём в одной структуре можно сделать несколько разных типов.
structPoint<T,U>{// <T> и <U> - 2 разных типа
x: T,y: U,}letinteger=Point{x:5,y:6};// в оба поля пишем числа типа i32
letfloat_int=Point{x:1,y:4.2};// в поля пишем разные типы i32 и f32
Аналогично неопределённые типы можно делать в перечислениях:
enumOption<T>{Some(T),// <T> - возможное значение любого типа, которое может быть или нет
None,}enumResult<T,E>{Ok(T),// T - тип результата успешной операции
Err(E),// Е - тип ошибки
}
Методы со структурами с неопределёнными типами
Можно прописать методы над данными неопределённого типа. Важно в заголовке метода указывать при этом неопределённый тип, чтобы помочь компилятору отделить его от обычного типа данных. Можно при этом сделать реализацию для конкретных типов данных, например, расчёт расстояния до точки от центра координат будет работать только для чисел с плавающей точкой. Для других типов данных метод расчёта работать не будет:
structPoint<T>{x: T,y: T,}impl<T>Point<T>{// указываем неопределённый тип в заголовке
fnshow_x(&self)-> &T{// метод возвращает поле данных
&self.x}}implPoint<f32>{// указываем конкретный тип float в методе,
// чтобы только для него реализовать расчёт. Для не-float метод не будет работать
fndistance_from_origin(&self)-> f32{(self.x.powi(2)+self.y.powi(2)).sqrt()}}fnmain(){letp=Point{x:5,y:6};println!("P.x = {}",p.show_x());// вызов метода для экземпляра p
}
Tip
Код с неопределёнными типами не замедляет производительность, потому что компилятор проходит и подставляет конкретные типы везде, где видит generics (“monomorphization” of code).
Итераторы позволяют выполнять действия по очереди над цепочкой данных. Итератор берёт каждый объект цепочки и проверяет, не последний или он. Итераторы в Rust - ленивые, т.е не отрабатывают, пока не будет вызван метод, который их поглощает.
iter()
Возвращает Iterator<Item = &T>, забирает на себя массив без изменений (immutable), поэтому исходный массив далее доступен для других действий. Применять для задач чтения.
letv1=[1,2,3];letv1_iter=v1.iter();forvalinv1_iter{// iterator consume by for cycle
println!("Got: {val}");}println!("{v1:?}");// v1 доступен после итератора
into_iter()
Возвращает Iterator<Item = T>, делает move массиву, после применения массив использовать нельзя. Применять для задач изменений с исходным массивом.
letv1=[1,2,3];fornuminv1.into_iter(){println!("{}",num);}// num is i32 (owned value)
// println!("{v1:?}"); // ❌ ошибка, v1 перемещён
Когда ты пишешь for x in коллекция, Rust автоматически вызывает into_iter(), потому что это “по умолчанию” забирает коллекцию. Если хочешь оставить коллекцию, явно используй for x in коллекция.iter().
iter_mut()
Возвращает Iterator<Item = &mut T>, забирает на себя массив с возможностью его менять прямо на месте. Исходный массив далее доступен для других действий.
letmutvec=vec![1,2,3];// Создает iterator по mutable rссылкам (&mut T)
fornuminvec.iter_mut(){*num*=2;}// можно менять элементы
println!("Modified: {:?}",vec);// [2, 4, 6]
Цикл for с iter(), into_iter(), iter_mut()
Синтаксический сахар:
letvec=vec![1,2,3];forxinvec.iter(){/* x: &i32 */}forxin&vec{/* x: &i32 */}// равно iter()
forxinvec.into_iter(){/* x: i32 */}forxinvec{/* x: i32 */}// равно into_iter()
forxinvec.iter_mut(){/* x: &mut i32 */}forxin&mutvec{/* x: &mut i32 */}// равно iter_mut()
Характеристика
iter
into_iter
iter_mut
Что возвращает
Ссылки (<T>)
Сами значения (T)
Изменяемые ссылки (<mut T>)
Можно ли менять элементы
Нет, только смотреть
Да, но коллекция уже твоя
Да, через ссылки
Что с коллекцией
Остаётся живой
“Исчезает” (перемещается)
Остаётся живой
Тип итератора
Итератор по ссылкам
Итератор по значениям
Итератор по изменяемым ссылкам
Когда использовать
Хочу посмотреть элементы
Хочу забрать элементы
Хочу изменить элементы на месте
Требуется ли mut для коллекции
Нет
Нет (но коллекция уходит)
Да, коллекция должна быть mut
Пример кода
for x in vec.iter()
for x in vec.into_iter()
for x in vec.iter_mut()
Пример результата
x — ссылка, vec жив
x — значение, vec мёртв
x — изменяемая ссылка, vec жив
repeat, repeat_n, take, skip
repeat - создаёт строку, повторяя заданный символ N раз (N as usize).
Например, вывести квадрат из символов “+” размера n (через клонирование):
skip(n) создаёт новый итератор, в котором пропускает заданное число n элементов исходного итератора, а остальные возвращает. С помощью него удобно обрабатывать данные, пропустив заголовок, либо параметры введённой команды с пропуском имени самой команды:
usestd::env;fnmain(){// env::args() = итератор на Strings с аргументами.
// Вызываем skip(1) для пропуска пути к команде.
letarguments=env::args().skip(1);// Клонируем clone() для проверки количества аргументом
// сохраняя исходный итератор
ifarguments.clone().count()==0{println!("No arguments provided other than the program name.");}else{println!("Processing arguments:");forarginarguments{println!(" Argument: {}",arg);}}}
Вместе take() и skip() комбинируются, чтобы получить средние значения в массиве:
letdata=[10,20,30,40,50,60,70,80];letiter=data.iter();letmiddle_elements: Vec<_>=iter.skip(2)// пропуск 2 элементов
.take(3)// взять 3 элемента = 30,40,50
.collect();// поместить результат в Vec.
println!("Middle elements: {:?}",middle_elements);
Отличие .map() и .flat_map()
Обе функции раскрывают итератор вектора, однако, с разным результатом:
peekable() превращает обычный итератор в итератор, который позволяет посмотреть на следующий элемент, не продвигая итератор вперед.
letmutnumbers=vec![1,2,3].into_iter().peekable();// peek() - смотрим на следующий элемент, но не двигаем итератор
println!("Смотрим: {:?}",numbers.peek());// Some(1)
println!("Смотрим ещё раз: {:?}",numbers.peek());// Все ещё Some(1)
println!("Берём: {:?}",numbers.next());// Some(1)
println!("Теперь смотрим: {:?}",numbers.peek());// Some(2)
println!("Берём: {:?}",numbers.next());// Some(2)
println!("Берём: {:?}",numbers.next());// Some(3)
println!("Теперь смотрим: {:?}",numbers.peek());// None
next_if() - взять элемент только если условие выполняется
letmutnums=vec![1,3,5,2,4].into_iter().peekable();// Берём все нечетные числа подряд
whileletSome(num)=nums.next_if(|x|*x%2==1){println!("{}",num);}// 1, 3, 5
Пример
Взятие символов в строке так, чтобы разбивать строку на пары из двух символов. Если строка содержит нечетное количество символов, то недостающий второй символ последней пары должен быть заменен на символ подчеркивания (’_’).
fnsolution(s: &str)-> Vec<String>{letmutresult=Vec::new();letmutchars=s.chars().peekable();// Делаем итератор peekable
whileletSome(c1)=chars.next(){// Берём первый символ пары
letc2=chars.next().unwrap_or('_');// Второй или '_' если нет
result.push(format!("{}{}",c1,c2));// Собираем пару
}result}
Метки времени жизни сообщают компилятору, как долго ссылка действительна.
fnfoo<'input>(bar: &'astr){// ...
}
Имя меток может быть абсолютно любым.
Правила элизии (неявного использования) меток времени жизни
Каждая входная ссылка на функцию получает отдельное время жизни;
Если есть ровно одно входное время жизни, оно применяется ко всем выходным ссылкам;
Если есть несколько входных времен жизни, но одно из них — &self или &mut self, то время жизни self применяется ко всем выходным ссылкам.
Это означает, что вам нужно явно указывать времена жизни только в том случае, если у вас более одного входного времени жизни и ни одно из них не является &self или &mut self.
Заражение кода явными метками времени жизни
Если добавить метки времени жизни в структуру, например,
structFoo{bar: String}
оптимизировать в &str для предотвращения выделения памяти и превратить в:
structFoo<'a>{bar: &'astr}
то теперь нужно добавлять метки во все методы, которые используют эту структуру:
В данном коде компилятор не может предсказать, что данные, на которые указывают ссылки x и y, будут живыми к моменту выхода из функции (выдаст ошибку). При этом та или иная ссылка нужны, в зависимости от выполнения условия (та, где данные длиннее), а понять какая можно будет лишь во время запуска приложения. Поэтому необходимо уверить компилятор, что обе ссылки останутся рабочими до конца работы функции:
Обход применения явных меток времени с помощью умных указателей Rc и Arc
Можно использовать умные указатели, Rc (подсчет ссылок) или Arc (атомарный подсчет ссылок), чтобы разделить владение данными. Таким образом, не нужно беспокоиться о явных временах жизни, сохраняя при этом затраты на клонирование данных близкими к нулю:
// Платим за выделение памяти лишь 1 раз
lethello=Rc::new("Hello".to_string());// Дешёвая операция
lethello2=hello.clone();
Пример с x и y можно переписать с применением Rc для примера:
Причины для явного использования меток времени жизни
Причин в современном Rust всего две:
Существует узкое место в коде по производительности: Вы обнаружили медленный участок часто используемого кода, профилировали его и определили, что узкое место действительно вызвано выделением памяти. В этом случае имеет смысл использовать время жизни, чтобы избежать выделения памяти. (Альтернатива — реорганизовать ваш код, чтобы использовать лучший алгоритм и избежать «горячего пути» в первую очередь.)
Код библиотек, от которого зависит код Вашего приложения, требует аннотаций времени жизни (пример - html5ever). Здесь мало что можно сделать, кроме как искать альтернативы, которые не требуют меток времени жизни.
Макросы — это как “шаблоны кода”, которые генерируют код за тебя. Они работают до того, как программа начнет компилироваться. Ты пишешь правило: “если встретишь такую конструкцию, разверни её в такой код”.
В Rust есть два основных типа макросов:
Объявительные макросы — самые простые, создаются через macro_rules!
Процедурные макросы — более мощные, пишутся как полноценный код на Rust.
// Создаем макрос, который выводит "Привет!" 2 раза
macro_rules!hello2{()=>{println!("Привет!");println!("Привет!");};}fnmain(){// Используем макрос — он развернется в 2 строки кода
hello2!();}
Макросы с параметрами
В макросах macro_rules! параметры обозначаются знаком $ и имеют строго определённые типы фрагментов (fragment specifiers). Они говорят компилятору, что именно можно подставить на это место. Макросы в Rust, в отличие от функций, могут принимать разное число параметров.
Таблица сравнения
Тип
Что принимает
Пример
Когда использовать
expr
Выражение
5 + 3, x, foo()
Чаще всего
block
Блок в {}
{ let x = 5; x }
Несколько операторов
ident
Имя
my_var, MyType
Создание имён
ty
Тип
i32, Vec<String>
Параметризация типами
path
Путь
std::collections::HashMap
Доступ к модулям
tt
Дерево токенов
Любой фрагмент кода
Сложная обработка
literal
Литерал
42, "text", true
Константы
vis
Видимость
pub, pub(crate)
Генерация API
item
Элемент
fn foo() {}, struct S
Генерация целых элементов
meta
Атрибут
derive(Debug)
Генерация атрибутов
lifetime
Время жизни
'a, 'static
Работа со ссылками
Важное ограничение
Нельзя использовать expr когда нужно что-то, что обязательно должно заканчиваться точкой с запятой. Для этого есть stmt (но он нестабилен) или block.
expr
Макрос с параметрами expr (выражение, expression): любое валидное выражение Rust, которое возвращает значение:
// Макрос выводит текст несколько раз
macro_rules!повтори{// $раз:expr и $текст:expr - параметры
($раз:expr,$текст:expr)=>{for_in0..$раз{println!("{}",$текст);}};}fnmain(){повтори!(3,"Учу Rust!");// Выведет "Учу Rust!" 3 раза
}
Макрос с вариативными параметрами:
// Макрос, принимающий любое количество чисел
macro_rules!сумма{// Базовый случай: одно число
($a:expr)=>{$a};// Рекурсивный случай: число + остальные
($a:expr,$($rest:expr),*)=>{$a+сумма!($($rest),*)};}fnmain(){lets=сумма!(1,2,3,4,5);println!("Сумма: {}",s);// 15
}
block
Последовательность выражений в фигурных скобках. Отличается от expr тем, что принимает только блок кода, а не любое выражение:
macro_rules!выполнить_блок{($блок:block)=>{println!("Выполняем блок:");letрезультат=$блок;println!("Результат блока: {}",результат);};}fnmain(){выполнить_блок!({leta=5;letb=3;a*b});// ОШИБКА! Это не блок, а просто выражение
// выполнить_блок!(5 + 3);
}
ident
Любой идентификатор языка: имя переменной, функции, типа, модуля.
macro_rules!объяви_переменную{($имя:ident,$тип:ty,$значение:expr)=>{let$имя: $тип=$значение;};}macro_rules!распечатай{($имя:ident)=>{println!("{} = {}",stringify!($имя),$имя);};}fnmain(){объяви_переменную!(x,i32,42);объяви_переменную!(сообщение,String,"Привет".to_string());letвозраст=30;распечатай!(возраст);// выведет: возраст = 30
// ОШИБКА! Это не идентификатор
// распечатай!(5 + 3);
}
ty
Любое обозначение типа в Rust. Нужно, когда макрос должен работать с разными типами данных.
Один токен или группу токенов в скобках. Самый гибкий тип, но и самый сложный. Нужен для сложной обработки синтаксиса, парсинга, создания DSL.
macro_rules!распечатай_tt{($токен:tt)=>{println!("Токен: {}",stringify!($токен));};}macro_rules!повтори_tt{($($т:tt)*)=>{$($т)*$($т)*};}fnmain(){распечатай_tt!(hello);// идентификатор
распечатай_tt!(5);// число
распечатай_tt!(+);// оператор
распечатай_tt!((1+2));// группа в скобках (целое дерево)
letx=повтори_tt!(1+2*3);// станет: let x = 1 + 2 * 3 1 + 2 * 3;
}
path
Полный путь к элементу (с модулями и двоеточиями). Отличие от ident: ident — только одно имя без ::. path — цепочка имён с ::.
macro_rules!используй_функцию{($путь:path,$аргумент:expr)=>{letрезультат=$путь($аргумент);println!("Результат: {}",результат);};}fnмоя_функция(x: i32)-> i32{x*2}modutils{pubfnвспомогательная(x: i32)-> i32{x+10}}fnmain(){используй_функцию!(моя_функция,5);// простое имя
используй_функцию!(utils::вспомогательная,5);// полный путь
используй_функция!(std::cmp::max,5,10);// но это уже два аргумента
// (path не подходит для нескольких)
}
item
Целое определение элемента в Rust (функцию, структуру, impl, модуль и т.д.). Для генерации целых элементов на уровне модуля.
macro_rules!создай_тест{($имя:ident,$тело:item)=>{#[test]fn$имя(){$тело}};}создай_тест!(тест_сложения,{assert_eq!(2+2,4);});// Можно даже целую функцию вставить
создай_тест!(тест_с_функцией,{fnвспомогательная()-> i32{42}assert_eq!(вспомогательная(),42);});
meta
Содержимое атрибутов (для макросов, которые генерируют атрибуты).
Crate Root. При компиляции crate, компилятор ищет корень: src/lib.rs для библиотеки, либо src/main.rs для запускаемого файла (binary);
Модули. При декларировании модуля в crate root, например, mod test, компилятор будет искать его код в одном из мест:
Сразу после объявления в том же файле (inline);
В файле src/test.rs;
В файл src/test/mod.rs - старый стиль - писать код прямо в файле mod.rs, поддерживается, но не рекомендуется. Удобно делать объединение модуля через него для декомпозиции модуля, не более.
Подмодули. В любом файле, кроме crate root, можно объявить подмодуль, например, mod automa. Компилятор будет искать код подмодуля в одном из мест:
Сразу после объявления в том же файле (inline);
В файле src/test/automa.rs;
В файле src/test/automa/mod.rs - старый стиль - писать код прямо в файле mod.rs, поддерживается, но не рекомендуется. Удобно делать объединение модуля через него для декомпозиции модуля, не более.
Путь до кода. Когда модуль часть crate, можно обращаться к его коду из любого места этой crate в соответствии с правилами privacy и указывая путь до кода. Например, путь до типа robot в подмодуле automa будет crate::test::automa::robot;
Private/public. Код модуля скрыт от родительских модулей по умолчанию. Для его публикации нужно объявлять его с pub mod вместо mod;
Use. Ключевое слово use нужно для сокращения написания пути до кода: use crate::test::automa::robot позволяет далее писать просто robot для обращения к данным этого типа.
Note
Нужно лишь единожды внести внешний файл с помощью mod в дереве модулей, чтобы он стал частью проекта, и чтобы другие файлы могли на него ссылаться. В каждом файле с помощью mod не надо ссылаться, mod - это НЕ include из Python и других языков программирования.
Для примера, возьмём библиотеку, обеспечивающую работу ресторана. Ресторан делится на части front - обслуживание посетителей, и back - кухня, мойка, бухгалтерия.
Объявление модуля публичным с помощью pub не делает его функции публичными. Нужно указывать публичность каждой функции по отдельности:
modfront_of_house{pubmodhosting{// модуль публичен, чтобы к нему обращаться
pubfnadd_to_waitlist(){}// функция явно публична
// несмотря на публичность модуля, к функции обратиться нельзя
// если она непублична
}}pubfneat_at_restaurant(){// Абсолютный путь через корень - ключевое слово crate
crate::front_of_house::hosting::add_to_waitlist();// Относительный путь
front_of_house::hosting::add_to_waitlist();}
Обращние к функции выше уровнем
Относительный вызов функции можно сделать через super (аналог “..” в файловой системе):
fndeliver_order(){}modback_of_house{fnfix_incorrect_order(){cook_order();super::deliver_order();// вызов функции в родительском модуле
}fncook_order(){}}
Обращение к структурам и перечислениям
Поля структур приватны по умолчанию. Обозначение структуры публичной с pub не делает её поля публичными - каждое поле нужно делать публичным по отдельности.
modback_of_house{pubstructBreakfast{// структура обозначена как публичная
pubtoast: String,// поле обозначено публичным
seasonal_fruit: String,// поле осталось приватным
}implBreakfast{pubfnsummer(toast: &str)-> Breakfast{Breakfast{toast: String::from(toast),seasonal_fruit: String::from("peaches"),}}}}pubfneat_at_restaurant(){// Обращение к функции. Без функции к структуре с приватным полем
// не получится обратиться:
letmutmeal=back_of_house::Breakfast::summer("Rye");// запись в публичное поле:
meal.toast=String::from("Wheat");println!("I'd like {} toast please",meal.toast);// если раскомменировать строку далее, будет ошибка компиляции:
// meal.seasonal_fruit = String::from("blueberries");
}
Поля перечислений публичны по умолчанию. Достатоно сделать само перечисление публичным pub enum, чтобы видеть все его поля.
С помощью as можно создать ярлык на объект в строке с use. Особенно это удобно в случае, когда нужно обратиться к одинаковым по имени объектам в разных модулях:
usestd::fmt::Result;usestd::io::ResultasIoResult;// IoResult - ярлык на тип Result в модуле io
fnfunction1()-> Result{// ... }
fnfunction2()-> IoResult<()>{// ... }
Ре-экспорт объектов
При обращении к объекту с помощью use, сам ярлык этот становится приватным - через него могут обращаться только функции текущего scope. Для того, чтобы из других модулей функции могли тоже обратиться через этот ярлык, нужно сделать его публичным:
modfront_of_house{pubmodhosting{pubfnadd_to_waitlist(){}}}pubusecrate::front_of_house::hosting;// ре-экспорт объекта
pubfneat_at_restaurant(){hosting::add_to_waitlist();// обращение к функции через ярлык
}
Работа с внешними библиотеками
Внешние библиотеки включаются в файл Cargo.toml. Далее, публичные объекты из них заносятся в scope с помощью use.
Если нужно внести несколько объектов из одной библиотеки, то можно сократить количество use:
//use std::cmp::Ordering;
//use std::io;
usestd::{cmp::Ordering,io};// список объектов от общего корня
//use std::io;
//use std::io::Write;
usestd::io{self,Write};// включение самого общего корня в scope
usestd::collections::*;// включение всех публичных объектов по пути
Warning
Следует быть осторожным с оператором glob - *, так как про внесённые с его помощью объекты сложно сказать, где именно они были определены.
Объявленная переменная, обеспеченная памятью кучи (heap) - общей памятью (не стека!) всегда имеет владельца. При передаче такой переменной в другую переменную, либо в функцию, происходит перемещение указателя на переменную = смена владельца. После перемещения, нельзя обращаться к исходной переменной.
lets1=String::from("hello");// строка в куче создана из литералов в стеке
lets2=s1;// перемещение
println!("{}, world!",s1);// ошибка! Вызов перемещённой переменной
Решения
Можно сделать явный клон переменной со значением;
lets1=String::from("hello");lets2=s1.clone();// полный клон. Медленно и затратно,
println!("s1 = {}, s2 = {}",s1,s2);// но нет передачи владения
Передавать ссылку на указатель. Ссылка на указатель - ‘&’, раскрыть ссылку на указатель - ‘*’.
fnmain(){lets1=String::from("hello");letlen=calculate_length(&s1);// передача ссылки на указатель
println!("The length of '{}' is {}.",s1,len);}fncalculate_length(s: &String)-> usize{// приём ссылки на указатель
s.len()}
Ссылки (References)
Для внесения изменений по ссылке на указатель, нужно указать это явно через ‘mut’.
fnmain(){letmuts=String::with_capacity(32);// объявить размер блока данных заранее, чтобы потом не довыделять при закидывании данных в строку = быстрее
change(&muts);// передача изменяемой ссылки
}fnchange(some_string: &mutString){// приём изменяемой ссылки на указатель
some_string.push_str("hello, world");}
Tip
Правила:
В области жизни может быть лишь одна изменяемая ссылка на указатель (нельзя одновременно нескольким потокам писать в одну область памяти);
Если есть изменяемая ссылка на указатель переменной, не может быть неизменяемых ссылок на указатель этой же переменной (иначе можно перезаписать данные в процессе их же чтения);
Если ссылка на указатель переменной неизменяемая, можно делать сколько угодно неизменяемых ссылок на указатель (можно вместе читать одни и те же данные);
Конец жизни ссылки определяется её последним использованием. Можно объявлять новую ссылку на указатель, если последняя изменяемая ссылка по ходу программы более не вызывается.
Кратко правила зовутся Aliasing XOR Mutability:
&T-> &sharedT&mutT-> &uniqueT
letmuts=String::from("hello");{letr1=&muts;}// r1 вышла из области жизни, поэтому можно объявить новую ссылку на указатель.
letr2=&muts;
Отображение ссылок
Для показа адресов ссылок можно использовать форматирование {:p}:
fnmain(){leta=10;letb=&a;letc=&b;// двойная ссылка. Разыменовывание через **b
letd=b;println!("{:p}\n{:p}\n{:p}\n{:p}\n",&a,b,c,d);// для отображения указателя на само число a, нужно указать &a
}
Если нужно работать с штучним объектом, вдобавок менять у него сразу много полей, то лучше SoA. Use case: RPG игра (тыкаешь в одного персонажа), БД (достаешь одну запись), редактор (меняешь один объект):
// Работа с ОДНИМ объектом
fnfeed_oldest_animal(animals: &mut[Animal]){letoldest=&mutanimals[0];// берем 1 животное
oldest.health+=10.0;// работаем со всеми полями сразу
oldest.hunger-=5.0;}
ECS: Data-Oriented Design
Сложно поддерживать код SoA. На помощь в Rust приходят ECS (Entity Component System). Примеры - Bevy ECS, Hecs, Legion. ECS абстрагирует работу с памятью. Вы пишете компоненты как маленькие структуры:
А затем пишете Системы (функции), которые запрашивают только то, что им нужно:
// Пример из Bevy ECS
fnphysics_system(mutquery: Query<(&mutPosition,&Velocity)>){for(mutpos,vel)inquery.iter_mut(){pos.x+=vel.dx;pos.y+=vel.dy;}}
ECS-фреймворк сам раскладывает компоненты в памяти в виде плотных массивов (почти как SoA, чаще всего используя паттерн Archetypes). Когда physics_system запрашивает данные, то бежит по памяти линейно, идеально утилизируя кэш.
Array of Structs (AoS)
Если надо сделать массовую операцию, то лучше AoS. Use cases: 3D-графика (двигаем 10,000 частиц), нейросети (матричные операции), аудиообработка (тысячи сэмплов):
// Обновляем всех сразу
fnupdate_all_positions(particles: &mutParticles){// Векторизация! +SIMD ускоряет +х10 скорости
foriin0..particles.positions.len(){particles.positions[i].x+=particles.velocities[i].x;}}
“Hybrid” Arrays (AoSoA)
А есть вариант менять объекты подмножествами. То есть по несколько штук, но не все. Тогда гибридный подход AoSoA. Use case: комп игры, 3D-графика (эмиттеры частиц):
// Группируем по 8 частиц в "пачку"
structParticlePack{x: [f32;8],// 8 позиций X
y: [f32;8],// 8 позиций Y
vx: [f32;8],// 8 скоростей X
}letmutgame: Vec<ParticlePack>;// массив пачек
Проблема конструктора в том, что он не привязан к контексту. Что именно определяется - температура морозильника? Тёплого солнечного дня? Температура тела больного пациента? - для default() абсолютно всё равно.
Добавка контекста с new:
implSmartThermometer{// определяем начальную Т
pubfnnew(initial_temp: f32)-> Self{SmartThermometer{current_temperature: initial_temp,}}// можно оставить default(), когда надо начальное 36.6
}
Совместное использование
Внутри default() можно вызвать new() для предпочитаемых значений:
implDefaultforSmartThermometer{fndefault()-> Self{Self::new(36.6)// использует внутри new()
}}
Придание дополнительного смысла типу переменной. Например, строка String может быть использована для чего угодно, а нам нужно конкретизировать:
// Обычный String
letname=String::from("john");// Newtypes - каждый тип уникален
structUsername(String);structEmail(String);structPassword(String);letuser=Username(String::from("john"));// Не перепутать типы
letemail=Email(String::from("john@example.com"));// Они разные!
У данного паттерна НЕТ стоимости в скорости или ресурсах приложения.
Применение
Защита от смешивания типов:
structMeters(f32);structKilometers(f32);fnrace_distance(distance: Meters){println!("Race is {} meters!",distance.0);}letm=Meters(100.0);letkm=Kilometers(0.1);race_distance(m);// ✅ Работает!
race_distance(km);// ❌ ОШИБКА! Нельзя передать КМ туда, где ждут М
pubstructCreditCardNumber(String);// клиенты видят этот метод
implCreditCardNumber{// Отдаём только безопасные методы
pubfnlast_four(&self)-> String{self.0[self.0.len()-4..].to_string()}// Внутренняя валидация происходит тут:
pubfnnew(number: String)-> Result<Self,String>{ifnumber.len()==16{Ok(CreditCardNumber(number))}else{Err("Must be 16 digits".to_string())}}}// Нельзя извне обратиться к сырой строке!
letcard=CreditCardNumber::new("1234567890123456".to_string()).unwrap();println!("{}",card.last_four());// "3456" ✅
// println!("{}", card.0); ❌ ОШИБКА! Приватное поле!
Когда использовать паттерн Newtype
Когда есть два значения одного типа, но означают разные вещи (IDs, измерения);
Когда надо добавить методы к типу, которым мы не владеем (например, обернуть u32, чтобы добавить is_even());
Когда надо применить правила валидации.
Когда НЕ использовать паттерн Newtype
Когда действительно нужны все методы исходного типа (вместо этого используйте псевдоним типа: type Age = u8).
У каждого класса/модуля/функции должна быть только одна причина для изменения.
Пример из жизни: кофемашина. Если она варит кофе, сама себя чистит, сама заказывает зёрна через интернет, печатает чеки - то это плохо! Если изменится способ печати чеков - придётся менять кофемашину. Если поставщик зёрен поменяет API - снова менять кофемашину.
Правильно: кофемашина только варит кофе. Чисткой занимается отдельный сотрудник, заказом зёрен — менеджер, печатью чеков — кассовый аппарат.
Пример антипаттерна в коде: SmartDevice::print_state() и хранит температуру, и выводит её в консоль:
implSmartDevice{pubfnprint_state(&self){println!("Текущая температура: {:.1}°C",...);// привязка к stdout
}}
Если потом потребуется писать отчёты в файл, отправлять по сети, выводить на веб-страницу, логировать в JSON, то придётся менять сам доменный тип, и это плохо!
Правильно: SmartDevice только хранит данные и отвечает за свою бизнес-логику. А за вывод отвечает кто-то другой.
Display
Антипаттерн без Display:
structPerson{name: String,age: u8,}implPerson{/// SRP нарушен: тип сам знает, как выводить в консоль
pubfnprint_info(&self){println!("Person: {} Age: {}",self.name,self.age);}}fnmain(){letperson=Person{name: "Alex".into(),age: 20,};person.print_info();// вывод только в консоль
}
Паттерн SRP с Display:
usestd::fmt;structPerson{name: String,age: u8,}implfmt::DisplayforPerson{fnfmt(&self,f: &mutfmt::Formatter<'_>)-> fmt::Result{write!(f,"{} {}",self.name,self.age)}}fnmain(){letperson=Person{name: "Alex".into(),age: 20,};println!("{}",person);// вывод в консоль
lettext=format!("{}",person);// вывод в строку
std::fs::write("out.txt",text).unwrap();// вывод в файл
}
Что такое f: &mut fmt::Formatter<'_>:
Содержание (self - то, что надо “напечатать”)
Лист бумаги (f - куда Вы это записываете)
fmt::Formatter - это как лист бумаги + ручка в одном флаконе. Он знает:
куда писать (в консоль, в строку, в файл)
какие настройки форматирования (ширина, выравнивание и т.д.)
Что происходит в println:
println! создаёт свой Formatter, который указывает на стандартный вывод
Вызывает person.fmt(&mut formatter)
Метод fmt пишет в этот formatter
println! добавляет перевод строки и отправляет в консоль
Debug and to String
Аналогичный паттерн SRP с Debug:
// Для отладки через {:?}
implfmt::DebugforPoint{fnfmt(&self,f: &mutfmt::Formatter<'_>)-> fmt::Result{write!(f,"Point({}, {})",self.x,self.y)}}// Для преобразования в строку
implFrom<Point>forString{fnfrom(point: Point)-> String{format!("({}, {})",point.x,point.y)}}
. any character except new line (includes new line with s flag)
[0-9] any ASCII digit
\d digit (\p{Nd})
\D not digit
\pX Unicode character class identified by a one-letter name
\p{Greek} Unicode character class (general category or script)
\PX Negated Unicode character class identified by a one-letter name
\P{Greek} negated Unicode character class (general category or script)
Классы символов
[xyz] A character class matching either x, y or z (union).
[^xyz] A character class matching any character except x, y and z.
[a-z] A character class matching any character in range a-z.
[[:alpha:]] ASCII character class ([A-Za-z])
[[:^alpha:]] Negated ASCII character class ([^A-Za-z])
[x[^xyz]] Nested/grouping character class (matching any character except y and z)
[a-y&&xyz] Intersection (matching x or y)
[0-9&&[^4]] Subtraction using intersection and negation (matching 0-9 except 4)
[0-9--4] Direct subtraction (matching 0-9 except 4)
[a-g~~b-h] Symmetric difference (matching `a` and `h` only)
[\[\]] Escaping in character classes (matching [ or ])
[a&&b] An empty character class matching nothing
Повторы символов
x* zero or more of x (greedy)
x+ one or more of x (greedy)
x? zero or one of x (greedy)
x*? zero or more of x (ungreedy/lazy)
x+? one or more of x (ungreedy/lazy)
x?? zero or one of x (ungreedy/lazy)
x{n,m} at least n x and at most m x (greedy)
x{n,} at least n x (greedy)
x{n} exactly n x
x{n,m}? at least n x and at most m x (ungreedy/lazy)
x{n,}? at least n x (ungreedy/lazy)
x{n}? exactly n x
Примеры
Замена всех совпадений в строке
Задача заменить строки, разделённые - или _ на CamelCase. При этом если строка начинается с заглавной буквы, то первое слово новой строки тоже с неё начинается:
Задача разбить переход от нижнего регистра к верхнему в camelCase пробелом:
useregex::Regex;fnsolution(s: &str)-> String{letre=Regex::new(r"[A-Z]").unwrap();// находим заглавную букву
re.replace_all(s," $0").to_string()// добавляем перед ней пробел
// $0 означает весь найденный текст
}// camelCasingTest -> camel Casing Test
// альтернативный вариант:
fnsolution(s: &str)-> String{Regex::new(r"([a-z])([A-Z])").unwrap().replace_all(s,"$1 $2").to_string()}// '$1 и $2' - найденные группы символов
Существует две основные категории программных бенчмарков: микро-бенчмарки и макро-бенчмарки. Микро-бенчмарки работают на уровне, аналогичном модульным тестам. Макро-бенчмарки работают на уровне, аналогичном интеграционным тестам.
В целом, лучше всего тестировать на максимально низком уровне абстракции. В случае бенчмарков это делает их более простыми в поддержке и помогает уменьшить количество шума в измерениях. Однако, как и наличие некоторых сквозных тестов может быть очень полезным для проверки того, что вся система работает как ожидается, так и наличие макро-бенчмарков может быть очень полезным для обеспечения того, чтобы критические пути в вашем программном обеспечении оставались производительными.
std::time для быстрого замера
usestd::time::Instant;fnarray_diff<T: PartialEq>(a: Vec<T>,b: Vec<T>)-> Vec<T>{a.into_iter().filter(|x|!b.contains(x)).collect()}fnarray_diff2<T: PartialEq>(muta: Vec<T>,b: Vec<T>)-> Vec<T>{a.retain(|x|!b.contains(x));a}fnmain(){letstart=Instant::now();// начало замера 1
println!("{:?}",array_diff(vec![1,2,2],vec![1]));letduration_a=start.elapsed();// конец
letstart=Instant::now();// начало замера 2
println!("{:?}",array_diff2(vec![1,2,2],vec![1]));letduration_b=start.elapsed();// конец
println!("Замеры: 1) {:?}; 2) {:?}",duration_a,duration_b);}
Для более точного замера следует собирать код с cargo run --release ключом.
Далее в проекте создать папку и файл benches\my_benchmark.rs:
usecriterion::{Criterion,criterion_group,criterion_main};fnarray_diff<T: PartialEq>(a: Vec<T>,b: Vec<T>)-> Vec<T>{a.into_iter().filter(|x|!b.contains(x)).collect()}// функция 1 для проверки
fnarray_diff2<T: PartialEq>(muta: Vec<T>,b: Vec<T>)-> Vec<T>{a.retain(|x|!b.contains(x));a}// функция 2 для проверки
fnbenchmark_functions(c: &mutCriterion){letmutgroup=c.benchmark_group("Function Comparison");group.bench_function("array_diff",|b|{b.iter(||{std::hint::black_box(array_diff(vec![1,2,2],vec![1]));})// black_box блокирует оптимизации компилятора
});group.bench_function("array_diff2",|b|{b.iter(||{std::hint::black_box(array_diff2(vec![1,2,2],vec![1]));})});group.finish();}criterion_group!(benches,benchmark_functions);criterion_main!(benches);
Для запуска тестов необходима команда cargo bench. Результаты замеров сохраняются и сравниваются с новыми результатами после внесения изменений.
flamegraph - визуализация стека вызовов
flamegraph — это инструмент для создания интерактивных SVG-диаграмм, которые визуализируют стек вызовов и время, затраченное в каждой функции. Он строится на основе данных от perf (xctrace в macOS) и помогает быстро понять, где сосредоточена нагрузка.
Установка:
cargo install flamegraph
Для того, чтобы видеть заголовки запускаемых функций (не их хэши), нужно в файле cargo.toml добавить профиль разработки. При этом профилирование скорости нужно проводить в режиме release со всеми оптимизациями, поэтому следует сделать отдельный профиль под release, но с debug-символами:
[profile.perfmon]inherits="release"debug=true
Использование:
# принудительно указать свой профиль perfmon (по умолчанию --release)cargo flamegraph --profile perfmon
# данные по выбранной функцииcargo flamegraph --profile perfmon --flamechart-opts "--grep functionName"# Профилирование unit-тестов# Разделитель `--` нужен, если `--unit-test` последний флаг.cargo flamegraph --unit-test -- test::in::package::with::single::crate
cargo flamegraph --unit-test crate_name -- test::in::package::with::multiple:crate
# Профилирование интеграционных тестовcargo flamegraph --test test_name
# Профилирование примера из папки examples в workspacecargo flamegraph --example some_example --features some_features
String printing, splitting, joining and formatting.
В Rust строки хранятся в формате UTF-8, где каждый символ может занимать от 1 до 4 байт. Поэтому индексация идёт не по символам напрямую, а по байтам или с учётом корректных границ символов (Unicode scalar values).
Пример строкового литерала:
lets="Hello, Rust!";// Обычная строка, строковый литерал
letraw=r#"Сырой текст с "кавычками""#;// Сырая строка без экранирования
String
Тип данных с владельцем. Имеет изменяемый размер, неизвестный в момент компиляции. Представляет собой векторную структуру:
pubstructString{vec: Vec<u8>;}// для ASCII символов
Поскольку структура содержит Vec, это значит, что есть указатель на массив памяти, размер строки size структуры и ёмкость capacity (сколько можно добавить к строке перед дополнительным выделением памяти под строку).
Работа с String: если у вас String, нужно сначала получить срез &str с помощью &
&str
Ссылка на часть, slice от String (куча), str (стек) или статической константы. Не имеет владельца, размер фиксирован, известен в момент компиляции.
&String можно неявно превращать в &str;
&str нельзя неявно превращать в &String.
fnmain(){lets="hello_world";letmutmut_string=String::from("hello");success(&mutable_string);fail(s);}fnsuccess(data: &str){// неявный перевод &String -> &str
println!("{}",data);}fnfail(data: &String){// ОШИБКА - expected &String, but found &str
println!("{}",data);}
Warning
Пока существует &str её в области жизни нельзя менять содержимое памяти, на которое она ссылается, даже владельцем строки.
&String
Ссылка на String. Не имеет владельца, размер фиксирован, известен в момент компиляции.
fnchange(mystring: &mutString){if!mystring.ends_with("s"){mystring.push_str("s");// добавляем "s" в конец исходной строки
}
str
Набор символов (литералов), размещённых на стеке. Не имеет владельца, размер фиксирован, известен в момент компиляции. Можно превращать str в String через признак from:
Если структуре надо владеть своими данными - использовать String. Если нет, можно использовать &str, но нужно указать время жизни (lifetime), чтобы структура не пережила взятую ей строку:
structOwned{bla: String,}structBorrowed<'a>{bla: &'astr,}fnmain(){leto=Owned{bla: String::from("bla"),};letb=create_something(&o.bla);}fncreate_something(other_bla: &str)-> Borrowed{letb=Borrowed{bla: other_bla};b// при возврате Borrowed, переменная всё ещё в области действия!
}
Разница между to_lowercase(), to_ascii_lowercase(), make_ascii_lowercase() и upper-аналогов
Функция
to_uppercase()
to_ascii_uppercase()
make_ascii_uppercase()
Возвращает
Новая String
Новая String
() (меняет входную строку)
Текст
Unicode
только ASCII
только ASCII
Память
Новая строка
Новая строка
Не выделяет память
Speed
Медленно
Быстро
Быстрее всех
Особенности
Обработка спец-символов (ß→SS)
Нет, пропускает спец-символы
Нет, пропускает спец-символы
Передача любых строк в функцию с переводом по ссылке
Можно воспользоваться встроенным типажом AsRef для перевода ссылок строки всех видов (String, &str, Box<str> и т.д.) в &str:
// AsRef<str> is a trait that allows cheap reference-to-reference conversion — here it guarantees we can get a `&str` from a value of type `N`:
fnhello<N: AsRef<str>>(name: N){println!("Hello, {}!",name.as_ref());// .as_ref() is from the `AsRef` trait — it converts `&name` into a `&str`.
}fnmain(){letstrings: Vec<String>=vec!["Alice".into(),"Bob".into()];// "Alice".into() равен String::from("Alice")
strings.into_iter().for_each(hello);hello("Charlie");hello(&String::from("Debbie"));hello(String::from("Evan").as_str());}
println!("{}",'a'asu8);// перевод символа в код ASCII
println!("{}",97aschar);// число как символ
// перевод кода UTF-8 в символ (не все символы можно перевести):
println!("{:?}",std::char::from_u32(98).unwrap());
Первая и последняя буква в строке
Чтобы проверить или изменить 1-ую букву в строке (в том числе иероглиф или иной вариант алфавита), нужно строку переделать в вектор из букв:
Есть функции sort() и sort_unstable() (работает быстрее, но равные элементы может перемешивать) для вектора символов Vec<char>. Обе функции делают сортировку на месте, возвращают ().
letinput="zxyabc";// сортировка Unicode тоже работает
letmutchar2vec_iter=input.chars().collect::<Vec<char>>();char2vec_iter.sort_unstable();// сортировка на месте
// char2vec_iter.sort_by(|a,b| b.cmp(a)); // реверс-сортировка
// собираем назад String из Vec<char>
letsorted_string: String=char2vec_iter.into_iter().collect();println!("{}",sorted_string);// "abcxyz"
chunks() и chunks_exact() разбиение строк на части
Аналогично массивам, строки можно разбить на части:
lettext="ПриветМир";letchars=text.chars().collect::<Vec<char>>();println!("Разбиваем строку на части по 3 символа:");forchunkinchars.chunks(3){lets: String=chunk.iter().collect();println!("{}",s);// При
// вет
// Мир
Строковые срезы
Срезы позволяют взять часть строки, указав диапазон байтовых индексов.
Синтаксис: &string[start..end] (где start — начало, end — конец, не включительно).
Особенность: нужно вручную следить за границами байтов, иначе будет паника при попытке разрезать строку посреди многобайтового символа.
lettext="Hello, world!";// тип &str
lettext=String::from("Hello, world!");// String
// Если у вас String, а не &str, нужно взять срез с помощью &:
letfirst_three=&text[0..3];// первые 3 символа
letlast_five=&text[text.len()-5..];// последние 5 символов
println!("{}",first_three);// "Hel"
println!("{}",last_five);// "orld!"
Отрицательные индексы в Rust не поддерживаются, поэтому нужно вычислять вручную. Если указать только начало ([start..]), берётся всё до конца:
Если строка содержит многобайтовые символы (например, кириллицу или эмодзи), простые байтовые срезы могут вызвать панику. Для работы с символами (Unicode scalar values) используйте метод .chars():
lettext="Привет, мир!";letchars: Vec=text.chars().collect();// преобразуем в вектор символов
letprivet: String=chars[0..6].iter().collect();// собираем первые 6 символов
println!("{}",privet);// "Привет"
Метод .chars() возвращает итератор по символам, а .collect() собирает их в нужный тип (например, String).
.get(start..end) для безопасного извлечения
Если нет уверенности в границах, и надо избежать паники, подойдёт метод .get() вместо прямого среза. Он возвращает Option<&str>:
Преимущество: проще для новичков, не нужно беспокоиться о байтовых границах.
Недостаток: добавляет внешнюю зависимость.
Примеры
Разворот букв в словах
Дана строка с пробелами между словами. Необходимо развернуть слова в строке наоборот, при этом сохранить пробелы.
fnreverse_words_split(str: &str)-> String{str.to_string().split(" ")// при разделении split() множественные пробелы сохраняются
.map(|x|x.chars().rev().collect::<String>())// разворот слов+сбор в строку
.collect::<Vec<String>>().// сбор всего в вектор
.join(" ")// превращение вектора в строку
}fnmain(){letword: &str="The quick brown fox jumps over the lazy dog.";println!("{}",reverse_words_split(&word));}// ehT kciuq nworb xof spmuj revo eht yzal .god
lets=String::from("Hello World!");letword=first_word(&s);println!("The first word is: {}",word);}fnfirst_word(s: &String)-> &str{// передача строки по ссылке
letword_count=s.as_bytes();for(i,&item)inword_count.iter().enumerate(){ifitem==b' '{return&s[..i];// возврат части строки как &str
}}&s[..]// обязательно указать возвращаемое значение, если условие в цикле выше ничего не вернёт (например, строка не содержит пробелов = вернуть всю строку)
‘Проход’ по строке итератором
Можно пройти по строке итератором chars() и его методами взятия N-го символа nth() спереди или nth_back() сзади:
letperson_name=String::from("Alice");println!("The last character of string is: {}",matchperson_name.chars().nth_back(0){// ищем 1-ый символ с конца строки
Some(i)=>i.to_string(),// если находим - превращаем в строку
None=>"Nothing found!".to_string(),// не находим = сообщаем
});
matches() и rmatches(),
Возвращают итератор с теми частями строки, которые совпадают с заданным шаблоном:
Возвращает Option<байт индекс 1го символа в строке слева-направо>, совпадающий с шаблоном. Либо возвращает None, если символ отсутствует в строке. rfind
fnduplicate_encode2(word: &str)-> String{lets=String::from(word).to_lowercase();s.chars().map(|c|ifs.find(c)==s.rfind(c){'('}else{')'}).collect()}// если у символа есть дубли => замена на '(',
// иначе на ')'
fnmain(){println!("{}",duplicate_encode("rEcede"));}
Use split(' '), filter out empty entries then re-join by space:
s.trim().split(' ').filter(|s|!s.is_empty()).collect::<Vec<_>>().join(" ")// Using itertools:
useitertools::Itertools;s.trim().split(' ').filter(|s|!s.is_empty()).join(" ")// Using split_whitespace, allocating a vector & string
pubfntrim_whitespace_v1(s: &str)-> String{letwords: Vec<_>=s.split_whitespace().collect();words.join(" ")}
Озаглавить каждое слово в предложении
В заданной фразе озаглавить каждое слово. Если результат больше 140 символов или пустой, вернуть None:
fncapitalize_first_letter(s: &str)-> Option<String>{letres=s.split_whitespace().map(capital)// каждое слово передать в функцию capital()
.collect::<Vec<String>>()// собрать в вектор
.join(" ");// потому что вектор можно собрать в string с join()
ifres.len()<141||!res.is_empty(){// проверка длины
Some(res)}else{None}}fncapital(word: &str)-> String{letmutlword=word.to_ascii_lowercase();// изменить НА МЕСТЕ - прямо в этой строке (быстрее всего):
lword[0..1].make_ascii_uppercase();lword// вернуть итоговую строку
}
Макрос println! позволяет вывести строку в поток stdout;
// println!("Hello there!\n");
// раскрывается в такой код:
usestd::io::{self,Write};io::stdout().lock().write_all(b"Hello there!\n").unwrap();
Макрос dbg!() позволяет вывести переменные и структуры в поток stdout;
split()
Метод split: разбивает строку на части по указанному разделителю и возвращает итератор. Разделитель может быть символом, строкой или даже пробелом. В том числе можно делить по нескольким символам разом:
lettext=String::from("the_stealth-warrior");letparts=text.split(['-','_']).collect::<Vec<&str>>();// collect собирает в коллекцию типа вектор
forpartinparts{println!("{}",part);
Другие методы разбивки
split_whitespace()
Разбивает по любым пробельным символам (пробелы, табы, переносы строк).
Нахождение закономерностей в структурах со строками
В примере мы передаём вектор из строк. Далее, анализируем его по частям:
fnlikes(names: &[&str])-> String{matchnames{[]=>"no one likes this".to_string(),[a]=>format!("{} likes this",a),[a,b]=>format!("{} and {} like this",a,b),[a,b,c]=>format!("{}, {} and {} like this",a,b,c),[a,b,other@..]=>format!("{}, {} and {} others like this",a,b,other.len()),}}
Struct - комплексный изменяемый тип данных, размещается в куче (heap), содержит внутри себя разные типы данных. Он похож на кортеж (tuple), однако типы данных должны иметь явные именования.
structUser{active: bool,username: String,email: String,sign_in_count: u64,// запятая в конце обязательна
}
Можно передать struct в функцию или вернуть из функции:
fnmain(){// создаём изменяяемый объект по структуре данных выше
letmutuser1=create_user(String::from("john@doe.com"),String::from("testuser"));println!("User Email is {}",user1.email);user1.email=String::from("Parker@doe.com");println!("User Email is {}",user1.email);}fncreate_user(email: String,username: String)-> User{// возврат из функции
User{active: true,username,email,// имена полей имеют с входными переменными, и можно не писать username: username, email: email.
sign_in_count: 1,}// return заменяется отсутствием знака ";"" как обычно
}
Updating Structs
Если нужно создать новую структуру по подобию старой, и большая часть полей у них похожи, то можно использовать синтаксический сахар:
letuser2=User{email: String::from("another@example.com"),// задать новое значение поля
..user1// взять остальные атрибуты из user1. Идёт последней записью
};
Важный момент: при передаче поля от user1 в user2 передаются через move. То есть user1 объект теперь использовать нельзя. Чтобы это поправить, можно копировать: добавить на структуру User трейты derive = Clone, и далее:
letuser2=User{email: String::from("another@example.com"),// задать новое значение поля
..user1.clone()// взять остальные атрибуты из user1 через клонирование!
};
Tuple structs
Структуры такого вида похожи на кортежи, но имеют имя структуры и тип. Нужны, когда нужно выделить кортеж отдельным типом, либо когда надо дать общее имя кортежу. При этом отдельные поля не имеют имён.
Переменные red и origin разных типов. Функции, которые берут Color как параметр, не возьмут Point, несмотря на одинаковые типы внутри. Каждая структура = свой собственный тип. Разбор таких структур на элементы аналогичен кортежам.
let(x,y,z)=(origin.0,origin.1,origin.2);
Unit-like structs
Структуры без полей аналогичны кортежам без полей, только с именем.
structTestTrait;fnmain(){test=TestTrait;}
Такие структуры нужны для задания признаков (traits), когда в самой структуре данные хранить не нужно. Их смысл заключается в том, чтобы представлять типы или маркеры, которые используются для передачи информации о структуре программы или её логике на уровне типов, а не для хранения данных.
Иногда нужно реализовать трейт (интерфейс) для типа, который не требует хранения данных. Юнит-структуры идеально подходят для этого:
Здесь Empty не хранит данных, но реализует интерфейс Display.
Структурные признаки
Можно выводить информацию о содержимом полей структуры для анализа кода. Для этого нужно добавить над структурой пометку debug:
#[derive(Debug)]structRectangle{width: u32,height: u32,}fnmain(){letscale=2;letrect=Rectangle{width: dbg!(20*scale),// вывод поля структуры. dbg! возвращает назад
height: 10,// взятое значение, с ним далее можно работать
};println!("Rectangle content: {:?}",rect);// вывод содержимого структуры
dbg!(&rect);// ещё вариант вывода - в поток stderr. Функция dbg!
// забирает владение структурой, поэтому передача по ссылке
}
Структурные методы
Можно добавлять функции как методы, привязанные к структурам. Это позволяет организовать код более чётко - по объектам и действиям над ними.
Для внесения изменений в объект структуры, в блоке методов можно объявить &mut self, а для перемещения владения - просто self. Это нужно изредка при превращении self в другой вид объекта, с целью запретить вызов предыдущей версии объекта. Внутри impl используется &self, чтобы метод мог обращаться к полям текущего экземпляра структуры, не передавая его явно как аргумент. Блоков impl может быть несколько.
Асоциированные функции
В блоке методов impl можно добавлять функции, которые первым параметром не берут саму структуру self. Обычно используются как конструкторы (например, для создания нового экземпляра структуры) или для других операций, не требующих доступа к данным экземпляра. Они вызываются через синтаксис :: (например, Rectangle::square), а не через точку (.), как методы:
implRectangle{fnsquare(size: u32)-> Rectangle{Rectangle{width: size,height: size}}// Используется блок `impl Rectangle` — это реализация для структуры `Rectangle` (предполагается, что она определена где-то выше, например, как `struct Rectangle { width: u32, height: u32 }`).
}fnmain(){letsq=Rectangle::square(5);println!("Square area: {}",sq.area());// Square area: 25
}
Создание типа данных с проверками
Вместо проверять введённые данные на корректность внутри функций, можно объявить собственный тип данных, содержащий в себе все необходимые проверки. Например, объявим число от 1 до 100 для игры, где надо угадать число:
pubstructGuess{// объявили тип данных (публичный)
value: i32,// внутри число (приватное)
}implGuess{pubfnnew(value: i32)-> Guess{// метод new проверяет значение
ifvalue<1||value>100{// на заданные границы 1-100
panic!("Guess value must be between 1 and 100, got {}.",value);}Guess{value}// возврат нового типа данных
}.// метод getter для получения значения value:
pubfnvalue(&self)-> i32{self.value// он нужен, тк напрямую видеть value нельзя
}// Это приватная переменная в структуре.
}
Представьте игру в LEGO:
Без типоориентированной разработки: мы начинаем строить случайные стены и крышу из того, что под руку попало, и надеемся, что в конечном итоге соберём дом.
С типоориентированной разработкой: мы сначала проектируем и определяем конкретные кирпичики LEGO, которые понадобятся: их формы, размеры и точки соединения.
Ход мышления: «Мне нужен кирпичик, который является дверью, кирпичик, который гарантирует, что он может держать крышу, и кирпичик, который обязательно должен иметь окно». Как только у нас определены нужные кирпичики, сборка становится простой, а компилятор выступает в роли помощника, гарантирует, что каждый выбранный кирпичик идеально встанет на свое место.
В Rust типы — это не просто данные для хранения. Это инструмент для обеспечения корректности, безопасности и бизнес-логики во время компиляции.
❗Философия такова: «Сделайте недействительные состояния непредставимыми».
Если логика программы гласит, что пользователь не может существовать без адреса электронной почты, то тип Rust для User даже не должен позволять вам создать его без электронной почты.
Как начать
На примере системы учёта сдачи в аренду книг в библиотеке:
Шаг 1: Понять предметную область и определить «существительные»:
Прежде чем писать какой-либо код, подумайте о реальных концепциях в вашем проекте. Каковы основные «вещи»? Примеры:
Книга:Вещь с названием, автором и уникальным идентификатором. Пользователь:Человек, который может брать книги. Выдача:Действие, связывающее Пользователя и Книгу на определенный период.
Шаг 2: Моделирование «существительных» как структур
Начните с определения основных структур данных. На этом этапе важно определить данные, которые они содержат, а не поведение.
// Простые типы для начала:
structBook{id: u32,title: String,author: String,}structUser{id: u32,name: String,// Активен ли пользователь? Определим позднее.
}structCheckout{book_id: u32,user_id: u32,checkout_date: String,// Слишком размыто, нужно уточнение
}
Шаг 3: Кодирование ограничений с помощью новых типов
Первая проблема: id: u32 слишком гибок. Может ли Book быть создан с user_id по ошибке? - Да. Можете ли вы случайно передать ID Book там, где ожидается ID User? - Да.
На помощь идиома New Type: мы оборачиваем примитивные типы, чтобы придать им семантическое значение.
// Создать обёртки для различия ID между собой
#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash)]// типовые traits для IDs
structBookId(u32);#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash)]structUserId(u32);// намного более чёткие структуры
structBook{id: BookId,// чёткий тип BookId
title: String,author: String,}structUser{id: UserId,// говорящий тип UserId
name: String,is_active: bool,// добавляем теперь активность пользователя
}structCheckout{book_id: BookId,// Компилятор теперь не даст перепутать IDs
user_id: UserId,checkout_date: String,// Всё ещё проблема
}
Компилятор теперь не позволяет писать checkout.user_id = BookId(5). Вы закодировали ограничение “ID пользователя должен быть UserId” непосредственно в систему типов.
Шаг 4: Используйте enum для моделирования состояний и альтернатив
Наш Checkout имеет String для даты. Это рискованно: что, если она пустая? Что, если она недействительная? Кроме того, книги имеют состояния. Книга может быть Available или CheckedOut. Ставим enum-типы: они позволяют определить набор возможных состояний.
// Тип для обозначения даты
usechrono::NaiveDate;// моделируем состояния книги
enumBookStatus{Available,CheckedOut{checkout: Checkout,// у взятой книги ЕСТЬ запись в реестре
},Lost,}// Book включает теперь status
structBook{id: BookId,title: String,author: String,status: BookStatus,// статус как чать типа
}// Checkout создаётся только при выписывании книги.
// Дата checkout_date теперь корректного типа, НЕ String.
structCheckout{user_id: UserId,checkout_date: NaiveDate,due_date: NaiveDate,}
С BookStatus невозможно иметь книгу, которая одновременно CheckedOut и Available. Система типов гарантирует, что книга находится в одном из трех определенных состояний.
Шаг 5: Используйте enum для результатов (тип Result)
Ваши функции должны использовать тип Result для кодирования возможности сбоя. Это заставляет вызывающую сторону обрабатывать ошибки.
Возвращаемый тип Result<Checkout, CheckoutError> говорит любому, кто использует эту функцию: “Эта операция может завершиться неудачей, и вот точные способы, которыми она может завершиться неудачей”. Компилятор заставляет их обрабатывать как случаи Ok, так и Err.
Шаг 6: Используйте трейты для общего поведения
Трейты определяют, что могут делать типы. Когда у вас есть свои типы, вы можете обнаружить, что они имеют общее поведение. Например, и Book, и User имеют идентификаторы. Вы могли бы определить трейт для этого:
// trait определяет общее поведение
traitHasId{fnid(&self)-> u32;// Но наши IDs = BookId/UserId, а не u32. Ещё лучше!
}// Или, с нашими newtypes:
traitHasTypedId<T>{fnid(&self)-> &T;}implHasTypedId<BookId>forBook{fnid(&self)-> &BookId{&self.id}}implHasTypedId<UserId>forUser{fnid(&self)-> &UserId{&self.id}}
Необязательно планировать все характеристики заранее, но обдумывание общих моделей поведения помогает разрабатывать гибкие, повторно используемые компоненты.
Короткий чеклист
Identify Nouns: List the core concepts (Book, User, Checkout).
Start with structs: Define the data these concepts hold. Don’t worry about behavior yet.
Replace Primitives with New Types: Wrap u32, String, etc., in struct wrappers (BookId, EmailAddress) to make the compiler enforce distinctions and constraints.
Model State with enums: If a concept can be in multiple, mutually exclusive states (Available vs. CheckedOut), use an enum. Aim to make invalid states unrepresentable.
Define Fallible Functions with Result: Before writing a function’s body, decide what its success and error types will be. This forces you to consider edge cases upfront.
Abstract with traits: Once types are stable, identify shared behaviors and define traits.
Эта философия превращает подверженные ошибкам проверки в runtime в гарантии во время компиляции. То есть, входные данные в программе нельзя тащить дальше в код. Нужно их на входе проверять и отсеивать. Т.е. вопросы: “а вдруг там ничего нет void/none, а вдруг пользователь ввёл некорректные данные?” - надо решать сразу на входной функции чтения данных, и не тащить это по всей программе, везде делая реверанс в стиле “а если там в начале ничего не было, то… "
В Rust это можно и нужно зашивать в типы данных, которые гарантируют наличие контента.
Пример: непустой массив
Допустим, я создаю тип для дома, в котором будет массив комнат. Массив комнат в доме априори не может быть пустым - хотя бы одна комната должны быть!
Вариант 1 - валидация в конструкторе
pubstructHouse{rooms: Vec<Room>,}implHouse{/// Конструктор, возвращающий Result - не может создать пустой дом
pubfnnew(rooms: Vec<Room>)-> Result<Self,&'staticstr>{ifrooms.is_empty(){Err("House must have at least one room")}else{Ok(House{rooms})}}
usenonempty::NonEmpty;pubstructHouse{rooms: NonEmpty<Room>,// Гарантированно не пустой список
}implHouse{/// Конструктор, принимающий как минимум одну комнату
pubfnnew(first_room: Room,rest_rooms: Vec<Room>)-> Self{letmutrooms=NonEmpty::new(first_room);rooms.extend(rest_rooms);House{rooms}}
Вариант 3 - собственный тип
Создаём собственный тип данных, аналог NonEmpty:
usestd::ops::{Index,IndexMut};/// Вектор, который гарантированно содержит хотя бы один элемент
#[derive(Debug, Clone)]pubstructNonEmptyVec<T>{first: T,rest: Vec<T>,}impl<T>NonEmptyVec<T>{/// Создает новый NonEmptyVec с одним элементом
pubfnnew(first: T)-> Self{NonEmptyVec{first,rest: Vec::new(),}}/// Создает NonEmptyVec из Vec, возвращая None если вектор пуст
pubfnfrom_vec(mutvec: Vec<T>)-> Option<Self>{ifvec.is_empty(){None}else{letfirst=vec.remove(0);Some(NonEmptyVec{first,rest: vec,})}}/// Создает NonEmptyVec из Vec, паникуя если вектор пуст
pubfnfrom_vec_unchecked(vec: Vec<T>)-> Self{assert!(!vec.is_empty(),"Cannot create NonEmptyVec from empty vector");letmutvec=vec;letfirst=vec.remove(0);NonEmptyVec{first,rest: vec,}}/// Создает NonEmptyVec из итератора, возвращая None если итератор пуст
pubfnfrom_iter<I: IntoIterator<Item=T>>(iter: I)-> Option<Self>{letmutiter=iter.into_iter();letfirst=iter.next()?;letrest: Vec<T>=iter.collect();Some(NonEmptyVec{first,rest})}/// Возвращает количество элементов
pubfnlen(&self)-> usize{1+self.rest.len()}/// Всегда возвращает false, так как NonEmptyVec никогда не пуст
pubfnis_empty(&self)-> bool{false}/// Получает ссылку на элемент по индексу
pubfnget(&self,index: usize)-> Option<&T>{ifindex==0{Some(&self.first)}else{self.rest.get(index-1)}}/// Получает мутабельную ссылку на элемент по индексу
pubfnget_mut(&mutself,index: usize)-> Option<&mutT>{ifindex==0{Some(&mutself.first)}else{self.rest.get_mut(index-1)}}/// Возвращает ссылку на первый элемент
pubfnfirst(&self)-> &T{&self.first}/// Возвращает мутабельную ссылку на первый элемент
pubfnfirst_mut(&mutself)-> &mutT{&mutself.first}/// Возвращает ссылку на последний элемент
pubfnlast(&self)-> &T{self.rest.last().unwrap_or(&self.first)}/// Возвращает мутабельную ссылку на последний элемент
pubfnlast_mut(&mutself)-> &mutT{ifself.rest.is_empty(){&mutself.first}else{self.rest.last_mut().unwrap()}}/// Добавляет элемент в конец
pubfnpush(&mutself,value: T){self.rest.push(value);}/// Удаляет последний элемент, возвращая его
/// Гарантированно возвращает Some, так как всегда есть хотя бы один элемент
pubfnpop(&mutself)-> Option<T>{self.rest.pop().or_else(||{// Не можем удалить последний элемент, так как это сделает коллекцию пустой
// Вместо этого возвращаем None, сигнализируя, что удаление невозможно
None})}/// Удаляет последний элемент, паникуя если это был последний элемент
pubfnpop_unchecked(&mutself)-> T{self.rest.pop().expect("Cannot pop the last element of NonEmptyVec")}/// Вставляет элемент на указанную позицию
pubfninsert(&mutself,index: usize,value: T){ifindex==0{letold_first=std::mem::replace(&mutself.first,value);self.rest.insert(0,old_first);}else{self.rest.insert(index-1,value);}}/// Удаляет элемент по индексу, возвращая его
pubfnremove(&mutself,index: usize)-> Option<T>{ifindex==0{ifself.rest.is_empty(){// Не можем удалить последний элемент
None}else{letold_first=std::mem::replace(&mutself.first,self.rest.remove(0));Some(old_first)}}else{self.rest.remove(index-1).into()}}/// Создает итератор
pubfniter(&self)-> implIterator<Item=&T>{std::iter::once(&self.first).chain(self.rest.iter())}/// Создает мутабельный итератор
pubfniter_mut(&mutself)-> implIterator<Item=&mutT>{std::iter::once(&mutself.first).chain(self.rest.iter_mut())}/// Преобразует в Vec
pubfninto_vec(mutself)-> Vec<T>{letmutvec=Vec::with_capacity(self.len());vec.push(self.first);vec.append(&mutself.rest);vec}/// Применяет функцию ко всем элементам
pubfnmap<U,F>(self,mutf: F)-> NonEmptyVec<U>whereF: FnMut(T)-> U,{NonEmptyVec{first: f(self.first),rest: self.rest.into_iter().map(f).collect(),}}}// Реализация Index для удобного доступа по индексу
impl<T>Index<usize>forNonEmptyVec<T>{typeOutput=T;fnindex(&self,index: usize)-> &Self::Output{self.get(index).expect("Index out of bounds")}}// Реализация IndexMut для мутабельного доступа по индексу
impl<T>IndexMut<usize>forNonEmptyVec<T>{fnindex_mut(&mutself,index: usize)-> &mutSelf::Output{self.get_mut(index).expect("Index out of bounds")}}// Реализация IntoIterator для использования в циклах
impl<T>IntoIteratorforNonEmptyVec<T>{typeItem=T;typeIntoIter=std::vec::IntoIter<T>;fninto_iter(self)-> Self::IntoIter{self.into_vec().into_iter()}}// Реализация FromIterator для создания из итератора
impl<T>FromIterator<T>forNonEmptyVec<T>{fnfrom_iter<I: IntoIterator<Item=T>>(iter: I)-> Self{NonEmptyVec::from_iter(iter).expect("Cannot create NonEmptyVec from empty iterator")}}
Потоки - объект ОС, способ разделения работы ПО. На обработку потоков могут назначаться разные ядра, а могут и не назначаться. Потоки выгодно использовать тогда, когда они дают выигрыш во времени больше, чем время на их создание (на x86 процессорах = ~9000 наносек, на ARM процессорах = ~27000 наносек). Обычно, это интенсивные по вычислениям приложения. Для интенсивным по вводу-выводу приложений следует использовать async/await вместо потоков.
Пример создания:
fnhello_thread(){println!("Hello from thread")}fnmain(){println!("Hello from the MAIN thread");letthread_handle=std::thread::spawn(hello_thread);thread_handle.join().unwrap();// нужно соединить новый поток с главным
// потоком программы, иначе он может не успеть вернуть данные до
// завершения главного потока программы
}
Потоки являются владельцами данных, поэтому нужно передавать им данные перемещением, чтобы они были живы к моменту запуска потока:
fndo_math(i: u32)-> u32{letmutn=i+1;for_in0..10{n*=2;}n}fnmain(){println!("Hello from the MAIN thread");letmutthread_handles=Vec::new();// вектор указателей потоков
foriin0..10{letthread_handle=std::thread::spawn(move||do_math(i));thread_handles.push(thread_handle);// добавить поток к вектор
}forhinthread_handles.into_iter(){println!("{}",h.join().unwrap());// соединение потоков с главным.
}// и вывод результата каждого потока.
Разделение задачи на потоки
Простой вариант - поделить вектор со значениями на куски (chunks), и под обработку каждого куска сделать отдельный поток, после чего собрать потоки вместе:
fnmain(){constN_THREADS: usize=8;letto_add=(0..5000).collect::<Vec<u32>>();// вектор от 0 до 4999
letmutthread_handles=Vec::new();// вектор указателей потоков
letchunks=to_add.chunks(N_THREADS);// размер кусков разбиения
forchunkinchunks{letmy_chunk=chunk.to_owned();// обход borrow checker/lifetime
thread_handles.push(std::thread::spawn(move||my_chunk.iter().sum::<u32>()));// создание потоков с принадлежащими им данными
}// суммирование потоков-кусков в одно число
letmutsum: u32=0;forhandleinthread_handles{sum+=handle.join().unwrap()}println!("Sum is {sum}");}
Trait или типаж - это способ определения общего поведения для типов. Трейты позволяют абстрагироваться от конкретных типов и сосредоточиться на том, что эти типы умеют делать. Это как знак отличия, стикер с надписью, что у типа есть некое свойство:
traitPrintable{// объявление трейта
fnprint(&self)-> String;// определяем, что Trait делает. Трейт утверждает печать, значит, по контракту обязан быть метод печати.
fninto_tuple(self)-> (i32,i32);// модель владения &self или self
}structPoint{x: i32,y: i32,}implPrintableforPoint{// применяем Trait для типа данных
fnprint(&self)-> String{format!("Point: ({}, {})",self.x,self.y)// пишем сам код
}fninto_tuple(self)-> (i32,i32){// self вместо &self = владение
(self.x,self.y)// Point поглощён, превращён tuple
}}fnmain(){letp=Point{x: 3,y: 4};println!("{}",p.print());// Вывод: Point: (3, 4)
}
По модели владения: обычно данными нужно пользоваться ещё после применения методов, поэтому всегда нужно объявлять &self и менять на self только в случае ошибок компилятора (в задачах трансформации данных, перемещения/отправки по сети, явного уничтожения).
Инициализация типажа
При объявлении типажа можно оставить обязательную реализацию на потом, либо вписать реализацию функций в типаже по-умолчанию:
// типаж задаёт метод и ограничения по входным/выходным типам
traitLandVehicle{fnLandDrive(&self)-> String;}// типаж задаёт методы плюс их реализация по умолчанию
traitWaterVehicle{fnWaterDrive(&self){println!("Default float");}}
Применение типажей к структурам данных
Во время применения, если реализация по умолчанию была задана, то можно её переделать под конкретную структуру, либо использовать эту реализацию:
structSedan{}structRocketship{}// типаж LandVehicle не имеет реализации по умолчанию, реализуем тут
implLandVehicleforSedan{fnLandDrive(&self)-> String{format!("Car zoom-zoom!")}}// типаж WaterVehicle имеет выше реализацию по умолчанию, используем её
implWaterVehicleforRocketship{}
Наследование и объединение типажей
Типажи могут наследовать другие типажи с помощью синтаксиса trait NewTrait: OldTrait:
Любой тип, реализующий Displayable, обязан также реализовать Printable.
При объединении типажей, создаётся ярлык (alias). При этом каждый входящий в него типаж нужно отдельно применить к структуре данных. При этом можно также использовать реализацию определённых в типаже методов по умолчанию, либо написать свою.
// создание ярлыка
traitAmphibiousVehicle: LandVehicle+WaterVehicle{}// применение типажей к структуре
implAmphibiousVehicleforCarrier{}implLandVehicleforCarrier{fnLandDrive(&self)-> String{format!("Use air thrust to travel on land")}}implWaterVehicleforCarrier{}
Вызов методов экземпляра структуры определённого типажа
Типажи определяют, какие возможности есть у generic типа T:
fnmy_function<T>(value: T)-> TwhereT: SomeTrait+AnotherTrait{/* function body */}
Eq (Equality)
Проверяет равенство == или неравенство !=;
Включает PartialEq (проверяет только равенство) + гарантирует тождество;
// Без Eq типажа:
// ❌ не будет компилироваться ==
fnfind_value<T>(items: &[T],target: T)-> bool{items.iter().any(|x|x==&target)// Error
}// Добавим Eq trait:
fnfind_value<T>(items: &[T],target: T)-> boolwhereT: Eq// теперь можно использовать ==
{items.iter().any(|x|x==&target)// ✅ работает!
}
std::hash::Hash
Позволяет конвертировать значения в хэш;
Требуется для хранения в HashMap, HashSet, или других коллекций с хэшом;
Тип с Hash может быть ключом или значением словаря:
usestd::collections::HashSet;// Без Hash:
// ❌ не будет компилироваться - HashSet требует Hash
fncreate_set<T>(items: Vec<T>)-> HashSet<T>{items.into_iter().collect()// Error: T doesn't implement Hash
}// С Hash:
fncreate_set<T>(items: Vec<T>)-> HashSet<T>whereT: Eq+std::hash::Hash// требуется для HashSet
{items.into_iter().collect()// ✅ работает!
}
Clone
Позволяет дублировать значение;
Разрешает метод .clone();
Нужно для копирования значений без взятия владения.
// Без Clone:
fnduplicate_first<T>(items: &[T])-> Option<T>{items.first().map(|x|x)// Error: can't return T from &T
}// Включаем Clone:
fnduplicate_first<T>(items: &[T])-> Option<T>whereT: Clone// можно клонировать
{items.first().cloned()// ✅ работает! - создаёт копию
}
// Converting different errors into one type
implFrom<NetworkError>forAppError{fnfrom(error: NetworkError)-> Self{AppError::Network(error.to_string())}}// Now functions can use ? operator automatically:
fndo_stuff()-> Result<(),AppError>{letdata=connect_to_server()?;// NetworkError automatically becomes AppError!
Ok(())}
// Anyone with the "Flying" badge must have a method called fly
traitFlying{fnfly(&self);// Takes a reference to itself, returns nothing
}// Trait implementation
// Our hero
structSuperHero{name: String,}// Our enemy
structWickedWitch{name: String,}// We give both the Flying badge, but they implement it differently
implFlyingforSuperHero{fnfly(&self){println!("{} soars through the sky majestically!",self.name);}}implFlyingforWickedWitch{fnfly(&self){println!("{} cackles loudly as her broomstick rattles into the air!",self.name);}}// ONE function, that works on ANYTHING with the Flying badge:
// This function doesn't care if it's a hero or a witch.
// It just says: "Bring me anything with the 'Flying' badge."
fnrace_to_the_castle(flyer: &implFlying){println!("The race starts!");flyer.fly();// We know it can fly, because it has the badge!
println!("We made it to the castle!");}fnmain(){lethero=SuperHero{name: String::from("Captain Soar")};letwitch=WickedWitch{name: String::from("Elvira")};// Both work perfectly!
race_to_the_castle(&hero);race_to_the_castle(&witch);}
Turbofish
При этом можно написать функцию race_to_the_castle двумя способами:
// короткий способ, использовался ранее:
fnrace_to_the_castle(flyer: &implFlying){flyer.fly();}// Способ turbofish way (полный generic syntax):
fnrace_to_the_castle<F: Flying>(flyer: &F){flyer.fly();}
Короткий способ подходит для простых случаев, но ломается на сложных. Примеры, когда нужно переходить на turbofish:
Несколько параметров должны быть ОДИНАКОВОГО типа
Нужны два животных для битвы, и они обязаны быть одинакового типа:
// SHORTHAND: This allows a Cat and a Dog to be shuffled around
fnshuffle_pair(a: &implAnimal,b: &implAnimal){// 'a' could be a Cat, 'b' could be a Dog
}// TURBOFISH: This FORCES both to be the same type
fnshuffle_pair<T: Animal>(a: &T,b: &T){// a and b MUST be the same kind of animal
}fnmain(){letcat=Cat{name: String::from("Whiskers")};letdog=Dog{name: String::from("Rover")};// Works with shorthand (different types allowed)
shuffle_pair(&cat,&dog);// OK
// ERROR with turbofish (cat and dog are different types!)
// shuffle_pair::<Cat>(&cat, &dog); // 💥 Dog ≠ Cat
}
Тип данных на выходе равен типу на входе
// You put in a specific animal, you get THAT same type back
fnclone_animal<A: Animal+Clone>(original: &A)-> A{original.clone()// Returns the same type that went in
}fnmain(){letcat=Cat{name: String::from("Whiskers")};letcloned_cat=clone_animal(&cat);// We know cloned_cat is a Cat
}
Нужно НЕСКОЛЬКО типажей одновременно
// This thing must be Flying AND have a BattleCry
fndramatic_entrance<F: Flying+BattleCry>(fighter: &F){fighter.battle_cry();fighter.fly();}
Подготовим пример: есть рыцарь и маг, оба могут держать оружие, но оружие у каждого своё.
// Define a weapon type
structSword{damage: u32,}structWand{magic_power: u32,}// This trait says "I can hold some type of item W"
// The <W> is a placeholder waiting to be filled
traitCanHold<W>{fnhold(&self,item: W);fndescribe_held_item(&self)-> String;}
В данном случае c параметром типаж как пустой стикер или пустой знак отличия, где поле ещё не заполнено конкретикой. Заполним конкретику:
structKnight{name: String,}structWizard{name: String,}// The knight can hold a Sword specifically
implCanHold<Sword>forKnight{fnhold(&self,item: Sword){println!("{} grips the sword firmly! Damage: {}",self.name,item.damage);}fndescribe_held_item(&self)-> String{String::from("A heavy blade")}}// The wizard can hold a Wand specifically
implCanHold<Wand>forWizard{fnhold(&self,item: Wand){println!("{} twirls the wand gracefully! Power: {}",self.name,item.magic_power);}fndescribe_held_item(&self)-> String{String::from("A mystical wand")}}
Теперь добавим, что рыцарь может держать в руках ещё щит - и это тоже попадает в типаж, остаётся лишь +1 параметр добавить:
structShield{defense: u32,}// The knight can ALSO hold a Shield!
implCanHold<Shield>forKnight{fnhold(&self,item: Shield){println!("{} raises the shield! Defense: {}",self.name,item.defense);}fndescribe_held_item(&self)-> String{String::from("A sturdy shield")}}fnmain(){letknight=Knight{name: String::from("Arthur")};// The same knight can hold different items!
knight.hold(Sword{damage: 50});// Uses CanHold<Sword>
knight.hold(Shield{defense: 30});// Uses CanHold<Shield> - same trait, different weapon!
}
Без параметра типаж работает НЕ БУДЕТ: потому что нельзя тот же типаж CanHold несколько раз применять просто так. А с параметром - МОЖНО, главное, чтобы параметр W отличался. Тогда один рыцарь может иметь несколько знаков из одной семьи знаков.
// AsRef is defined like this (simplified):
traitAsRef<T>{fnas_ref(&self)-> &T;// "Turn myself into a reference to T"
}// String implements AsRef<str> - "I can act as a string slice reference"
implAsRef<str>forString{fnas_ref(&self)-> &str{// String can easily give a &str view of its contents
&self[..]}}// &str also implements AsRef<str> - "I'm already a str reference!"
implAsRef<str>for&str{fnas_ref(&self)-> &str{self// Just return myself, I'm already what you want
}}// PathBuf (a file path type) implements AsRef<Path>
implAsRef<Path>forPathBuf{fnas_ref(&self)-> &Path{// Give a Path view of the PathBuf
self.as_path()}}
то это значит “приму любой тип N, если у N есть знак/стикер AsRef”, и это означает, что N может превратиться в &str.
Пример с превращениями
Представим игру, где персонажи могут превращаться в драконов или зайцев:
structPlayer{name: String,}structDragon{fire_power: u32,}structRabbit{speed: u32,}// The polymorph trait: "I can transform into T"
traitPolymorph<T>{fntransform(&self)-> T;}// Player can polymorph into a Dragon
implPolymorph<Dragon>forPlayer{fntransform(&self)-> Dragon{println!("{} grows scales and wings!",self.name);Dragon{fire_power: 100}}}// Player can ALSO polymorph into a Rabbit
implPolymorph<Rabbit>forPlayer{fntransform(&self)-> Rabbit{println!("{} shrinks and grows fluffy ears!",self.name);Rabbit{speed: 200}}}fnmain(){letplayer=Player{name: String::from("Alex")};// Same player, same trait name, completely different transformations!
letdragon_form=player.transform();// Rust infers we want Dragon here
letrabbit_form: Rabbit=player.transform();// Explicitly ask for Rabbit
}
letletter='a';println!("{}",letterasu32-96);// = 97-96 = 1
leti=97u8;// только с u8 разрешено делать 'as char'
println!("Value: {}",iaschar);
Boolean type
bool type can be true or false. Non-integer - do NOT try to use arithmetic on these. But you can cast them:
trueasu8;falseasu8;
Mutability
By default, variables in Rust are immutable. To make a variable mutable, special mut identifier must be placed. Rust compiler may infer the variable type from the type of value.
letx=5;// immutable variable, type i32 guessed by Rust as default for numbers.
letmutx=5;// mutable variable
Shadowing
Variable names can be reused. This is not mutability, because shadowing always re-creates the variable from scratch. Previous variable value may be used:
letx=5;letx=x+1;// new variable created with value = 6
Constants
Constant values are always immutable and available in the scope they were created in throughout the whole program. Type of constant must always be defined. Constants may contain results of operations. They are evaluated by Rust compiler. List of evaluations: https://doc.rust-lang.org/stable/reference/const_eval.html
constONE_DAY_IN_SECONDS: u32=24*60*60;// type u32 MUST be defined
letphrase="Hello World";println!("Before: {phrase}");// Before: Hello World
letphrase=phrase.len();println!("After: {phrase}");// After: 11
Составные переменные
Кортеж / Tuple
Кортеж — это структура с фиксированным размером, которая может содержать элементы разных типов. Синтаксис: (T1, T2, ...).
lettup: (u32,f32,i32)=(10,1.2,-32,"hello");// Деструктуризация позволяет "разобрать" кортеж на отдельные переменные:
let(x,y,z,u)=tup;//Доступ осуществляется через точку и индекс (начиная с 0):
leta1=tup.0;leta2=tup.1;
Если нужен только один элемент, остальные можно игнорировать с помощью _:
Кортежи полезны для возврата нескольких значений из функции;
Как и массивы, они хранятся в стеке и имеют фиксированный размер;
Используйте кортежи, когда нужно объединить разнородные данные в одну сущность.
Массив / Array
Массив в Rust — это структура данных с фиксированным размером, которая хранит элементы одного типа. Его синтаксис: [T; N], где:
T — тип элементов (например, i32 для целых чисел),
N — количество элементов, известное на этапе компиляции.
fnmain(){// Простой массив из трёх чисел
letnumbers: [i32;3]=[1,2,3];// Массив с повторяющимся значением (5 элементов, все равны 0)
letzeros: [i32;5]=[0;5];println!("Numbers: {:?}",numbers);// Вывод: [1, 2, 3]
println!("Zeros: {:?}",zeros);// Вывод: [0, 0, 0, 0, 0]
// Доступ к элементам массива = по индексу (начиная с 0)
letfirst=numbers[0];letsecond=numbers[1];// accessing array elements
}
❗Попытка обратиться к несуществующему индексу (например, arr[3] для массива из трёх элементов) вызовет панику!
Особенности:
Размер массива фиксирован и не может измениться после создания;
Массивы хранятся в стеке (stack), что делает их быстрыми, но менее гибкими;
Используйте массивы, когда размер известен заранее и не будет меняться.
chunks(usize) - разбиение массива на куски с остатком
Можно разбивать срез на части заданного размера. Последний кусок может быть меньше указанного размера, если элементов не хватает.
letnumbers=[1,2,3,4,5,6,7];letchunks=numbers.chunks(3);// разбить на куски по 3
forchunkinchunks{println!("Чанк: {:?}",chunk);}// Вывод:
// Чанк: [1, 2, 3]
// Чанк: [4, 5, 6]
// Чанк: [7] <-- меньше размера 3!
chunks_exact(usize) - точное разбиение
Разбивает срез на части строго заданного размера. Остаток (если есть) доступен отдельно через метод remainder().
Естественное удаление при выходе из области видимости
Переменная выходит из области видимости (закрывающая фигурная скобка }), её память освобождается автоматически, если она владеет данными (например,String, Vec).
fnmain(){lettext=String::from("Hello");println!("{}",text);// "Hello"
// Здесь text всё ещё существует
}// text выходит из области видимости и память освобождается
// println!("{}", text); // Ошибка: text больше не существует
Очистка содержимого c clear()
fnmain(){letmuttext=String::from("Hello");text.clear();// очищает содержимое, но переменная остаётся
println!("{}",text);// "" (пустая строка)
}
Использование std::mem::drop
Для явного “удаления” переменной (освобождения её памяти) до конца области видимости можно использовать функцию std::mem::drop:
fnmain(){letmuttext=String::from("Hello");println!("{}",text);// "Hello"
std::mem::drop(text);// text "удаляется" (перестаёт существовать)
// println!("{}", text); // Ошибка: text больше не существует
}
drop принимает владение переменной и немедленно освобождает её память. После этого переменная становится недоступной.